Motivation and purpose
Within these decades, Computer Vision has published a great amount of impressive applications, such as autonomous cars, face recognition, anomaly detection etc, which usually appear in our daily life.
Computer vision is the most popular field nowadays, and we are still not familiar with related techniques such as machine learning and deep learning. So our project aims to realize the model of large scale 3D instance segmentation, and try different methods to improve its performance.
Model and Dataset
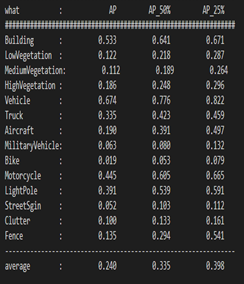
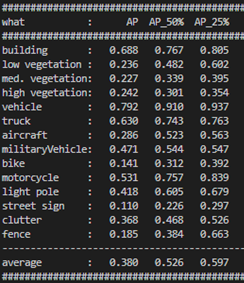
STPLS3D, Sematic Terrain Points Labeling – Synthetic 3D, is composed of both real-world and synthetic environments, which cover more than 17〖Km〗^2 of the city landscape in the U.S. with the high quality of per-point annotations and with up to 18 fine-grained semantic classes and 14 instance classes, which include building, low vegetation, medium vegetation, high vegetation, vehicle, truck, aircraft, military vehicle, bike, motorcycle, light pole, street sign, clutter, fence.

STPLS3D
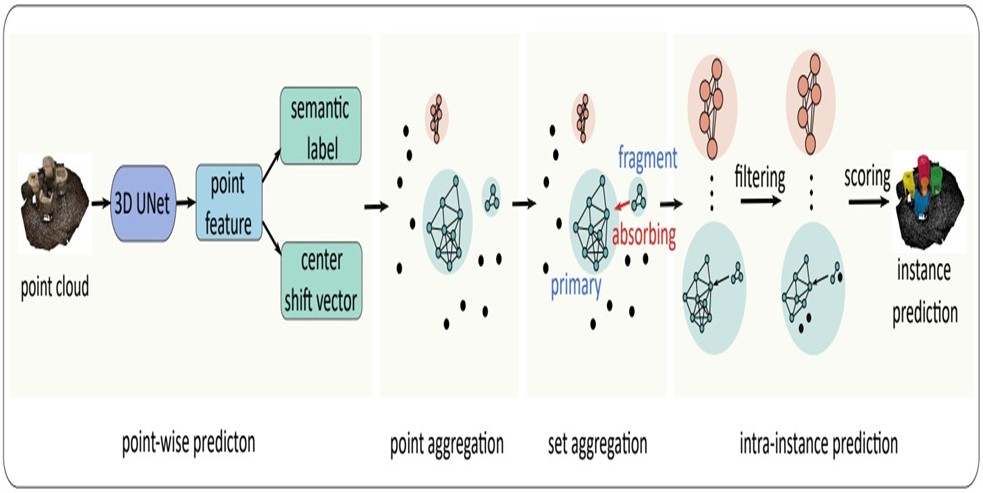
HAIS model
Hierarchical Aggregation for 3D Instance Segmentation Model
Point-wise prediction network
The model first extracts features from the point clouds and utilize the coordinates and colors information to predict point-wise semantic labels and venter-shift vectors. Point-wise feature learning is performed with the submanifold spare convolution, which is widely used in 3-dimension perception methods to extract features from point clouds.
Semantic Label Prediction Branch
This branch uses 2 layers of multilayer perception, which adopt gradient descent to obtain the best unbiased estimator, on the point features and a softmax layer to generate semantic scores for each class. The class with the highest score will be regarded as the predicted label of these points. Finally, the model utilizes cross-entropy to train this branch.
Point Aggregation
Based on the fact that points with the same instance in the 3 dimensional space are essentially adjacent, the initial instance can be obtained through the simplest clustering method. First, according to the calculated point-wise center offsetxi, the model shifts xi to its center by xishift = xiorigin+xi, then it discards the background points and treats the foreground points as nodes. Afterward, for rpoint, which has the same semantic label and a fixed clustering bandwidth will divide a line between the two nodes, background and foreground. After traversing all nodes and establishing edges, the entire point cloud is divided into multiple independent sets. Each set is a preliminary instance prediction.
Set Aggregation
But point aggregation is not a guarantee to the fact that all points in an instance are grouped correctly. Most points with the precise center offset predictions can be clustered together to form an incomplete preliminary instance prediction, called primary instancel while a few points with poor center offset predictions are split from the majority. These fragments have few points that can not be considered as complete instances, but missing parts of the incomplete primary instances. Considering the massive amount of fragments, it is irrational to simply dropout these groups directly within the threshold. Meanwhile, intuitively, if we look at the groups at the set-level, we can aggregate the primary instance and the fragment group to form a complete instance prediction.