
1. 摘要
這次專題的內容,是以Stephen Milborrow 的 STASM v1.5 [1] 為核心去加以改良,因為STASM v1.5 這個程式主要是針對無表情的正向人臉去找出特徵點,在判斷一些比較誇張的表情時一些特徵點的準確率並不是很理想,這次專題主要就是希望 能夠提高有表情人臉的特徵點準確率。
還把原本Command Line的程式加上 GUI,使其較為容易被使用者操作,也更容易觀看結果。另外還做了對連續影像的處理,嘗試去縮短處理的時間。
2. STASM
2.1 STASM Version 1.5
STASM 的全名為 Stacked Trimmed Active Shape Model 是 Stephen Milborrow 在論文 [1] 中所提出來的一個方法用以找出人臉中的特徵點。在論文中有詳細的介紹與說明,在這邊並不會詳述。
以上的演算法節錄自論文 [1] 的 Section 2.3,主要就是使用 Face Detector(Rowley [2] 或 Viola Jones [3]) 找到人臉的位置之後,會根據 Training 出來的 Models 給它一個 Start Shape,之後在從這個 Start Shape 去做 Translation, Rotation, Scaling 使這個 Shape 去符合所輸入的人臉。

Figure 2 就是 ASM Search 實際執行的過程,從一開始的 Shape 往人臉去做收斂。
2.2 STASM Version 1.5 的結果
在觀察過 STASM 對於一些有表情的人臉的執行結果之後發現,有時候特徵點的誤差還不小,比較明顯的部位就是嘴巴附近的點。
Figure 3 為一組 Database 中「快樂」表情的其中幾張圖,可以看出來,在眼睛、鼻子跟輪廓的結果都還算不錯,誤差比較大的就只有在嘴巴附近,這是因為 STASM 原本的設計就是給「無表情的正向人臉」做判斷用的,所以在判斷表情比較誇張的人臉時就會很容易產生誤差。
Figure 4 就是沒有表情的執行結果,可以看出來誤差比起 Figure 3 小了不少。減少嘴巴附近的特徵點的誤差就是這次專題的一個重點。


3. 改進方法
3.1 嘴角
在嘴巴附近的特徵點中,我們選擇先從嘴角開始調整。先以原本特徵點的座標找出包含整個嘴巴的一個矩形(利用原本的兩個嘴角以及鼻子最下面的一個點可以算出矩形的長跟寬),並將其轉換為灰階影像,如 Figure 5。

再對這張圖做 Histogram Stretch,把影像中的灰階值範圍拉到 0~255,使其對比更加明顯,Figure 6 為 Figure 5 做 Histogram Stretch 的結果。

由 Figure 6 可以明顯的看出來在整張影像中,嘴角是顏色最深的部份,為了使嘴角更明顯,我們選擇在 0~255 之間找出一個 Threshold 值,灰階值比Threshold小的點都會被設為 0,而比 Threshold大的都會被設為255,如此可以把一張灰階圖轉換為一張只有黑跟白兩種顏色的 Binary Image。
在實做時,我們是根據 Otsu 的演算法 [4] 來找出 Threshold 值。經過實驗之後發現,如果直接用原本的 Threshold 來做 Binary Image 的話效果並不理想,經過調整,最後選擇用原本 Threshold 的一半來做 Binary Image 效果會比較好,Figure 7 就是這個演算法處理之後的結果。
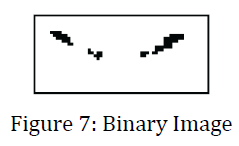
在 Figure 7 中,最左及最右邊的點分別就是兩邊的嘴角,因此在像 Figure 7 這樣的 Binary Image 中要找到嘴角,只要分別從最左邊跟最右邊開始由上往下一行行找,所找到的第一個點就會是嘴角。
3.2 嘴唇
找到了嘴角之後,接下來要修正的是嘴唇,在 STASM 所給的 Model 中,嘴唇總共有16個點,但我們實際去修正的只有9個點,其餘的點都是用這九個點以及嘴角的兩個點的相對位置去標定出來。
這九個點分別是上嘴唇的上緣、上嘴唇的下緣以及下嘴唇的上緣各三個。因為嘴唇的顏色變化沒有想嘴角那麼多,所以沒有辦法很簡單的從 Binary Image 中看出來。在這邊我們是使用 Gradient 來觀察並找出影像中的邊緣所在。Figure 8 為原本影像以及其 Gradient 的對照圖。

在這邊使用的計算 Gradient 方法,如 Figure 9 所示,X 方向的分量是用後一行剪前一行,Y 方向的是用後一列減前一列,最後一列與最後一行都設為0,最後再取平方和的平方根。在 Figure 8 中可以看出來,Gradient 就是用來凸顯邊緣用的,顏色變化越大的地方在 Gradient 的影像中會越明顯。

接下來我們就可以用原本嘴唇的座標在這張 Gradient Image 中找到新的座標點。以上嘴唇的上緣為例,可以求出三個點的座標在 Gradient Image 中的值,再把它加起來,就是這三個點的 Gradient 之和。在三個點的相對位置沒有改變的情況之下,每次往上移動一個 Pixel 再算一次 Gradient 的和,在找出這些和裡面的最大值,就是新的上嘴唇上緣。這個迴圈的執行次數為 Figure 5 中矩形之高的八分之一。以同樣的方法,使上嘴唇的下緣也往上移動,而下嘴唇的上緣是往下移動,如此就能求得新的座標。
3.3 整體
修正完嘴巴部位之後,接下來的步驟是對所有的點(共68個點)再做一次修正,修正的方法也是基於 Gradient Image。
跟嘴唇的方法類似,都是去找附近 Gradient 值比自己大的點作為新座標。在這個部份,搜尋的範圍,是以每個點為中心,尋找在 X±2以及Y±2 的範圍裡 Gradient 值比自己大的點,以其作為新座標。

在 Figure 10 中,左邊的圖是原本的結果,右邊是修正之後的結果,看得出來差異最多的部位就是嘴巴,不過在這張圖中上嘴唇的部位還是不夠準確。
4. 統計結果
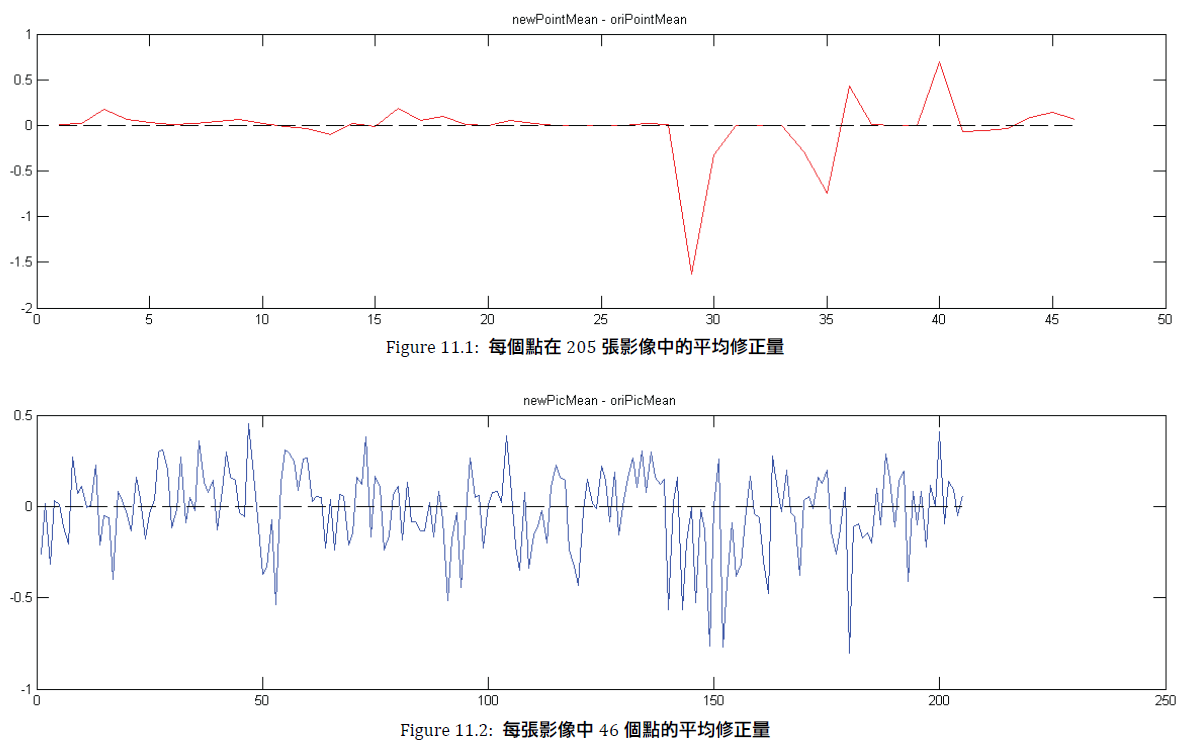
Figure 11 為對一組205張人臉影像的處理結果,因為每一張影像都有手動標定的特徵點,所以就以此為基準來比較修正前後的差異。
手動標定的特徵點有83個,而STASM 的輸出點有68個,經過比較之後,我們選擇了46個點為它們的交集,是以人工判斷的方式找出這些相對位置差不多的特徵點,也就是說沒有選到的點是因為沒有相對應的點。
Figure 11.1 為 newPointMean – oriPointMean。newPointMean 的意義為新得到的座標與手動標定的座標之距離,而 oriPointMean 為原本 STASM 的座標與手動標定的座標之距離,兩者相減就是修正前後的差距。圖中的橫軸分別為第1~第46個點,相對應的縱軸即為該點的平均修正量,單位為 Pixel,如果大於零就表示修正後距離變遠,而小於零就表示修正後的距離變近,單位是 Pixel。以Figure 11.1 的46個值而言,對於每個點平均下來是修正(變近)了 0.02 個 Pixel。
Figure 11.2 為 newPicMean – oriPicMean。newPicMean 的意義為修正之後,對於每張影像而言,新得到的座標與手動標定的座標之平均距離,而 oriPicMean 代表的則是修正之前的值。圖中橫軸所代表的就是第1~第205影像,相對應的縱軸即為該影像的平均修正量,單位跟 Figure 11.1 一樣都是 Pixel。因為是同一份資料做的統計,所以平均下來也是 𪙊0.02。
5. 加速連續影像的處理
這部份要改進的是對於連續影像的處理速度,可應用於表情動作影像的追蹤。原本的程式是把每一張輸入的影像都視為獨立的,分別對它們去做處理,彼此互不相干。如果現在的輸入是連續的好幾張影像,也就是連續的 Frame 的話,對於每一張影像都會做一次 Figure 2 的步驟,從最一開始的 Shape去做收斂。
因為是連續的影像,所以前後兩張 Frame 的差異不會太大。基於這個想法,我們另外提出針對連續影像的處理方式。也是就只有第一個 Frame 會從一開始的 Shape 開始做收斂,在第一張 Frame 之後的影像,都是用前一張影像收斂之後的結果作為其 Start Shape。用這個方法來省略人臉偵測以及前面收斂的步驟,已達到更快的處理速度。
在這個方法中,我們也只要對第一張 Frame 做 Face Detection,之後的 Frame 都不需要再做而是直接用第一張 Frame 的結果。這樣處理的效果,在人臉沒有太大的位移時是相當不錯的。
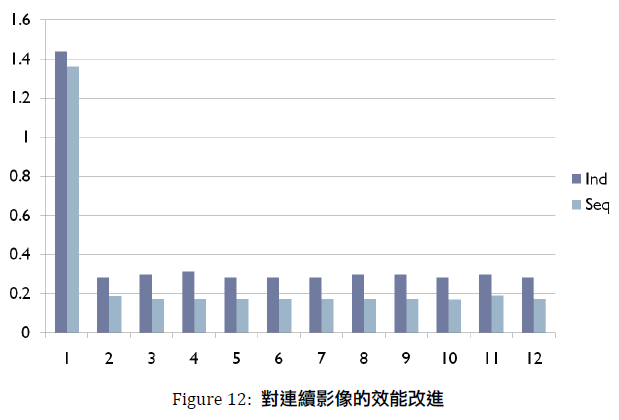
Figure 12 是對連續的12張影像處理所分別耗費的時間,深色( Ind,代表的是Independent )的是原本的方法,把這12張影像視為獨立的,分別去做處理。淺色( Seq,代表的是Sequential )的是用上述方法的執行結果。
不看第一張影像的話,其他的影像大概都縮短了30%~40% 的時間,總體而言縮短了29%的時間。第一張影像因為兩種方法所做的都差不多,所以時間沒有太大的差距。
至於為什麼原本的方法也會使得第二個以後的處理時間也縮短,我們猜測可能是因為第二個以後直接使用第一個的記憶體空間,不用再花太多時間配置,所以使存取的時間縮短。
6. 使用者圖形介面
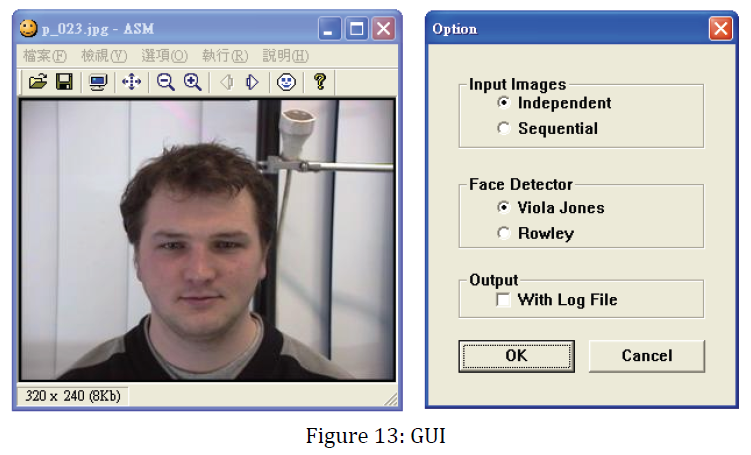
此程式的核心是 STASM v1.5,而圖形介面是修改自 The Yovav (Horror) PictureShow Version 1.00 [5]。此外還加上一些可以讓使用者選擇的選項,如 Figure 13 的右圖所示,使用者可以選擇輸入的影像種類、人臉偵測器、輸出除了影像之外還要不要輸出特徵點的座標。
7. 結論
因為目前只有學過簡單的影像處理技巧,從統計上的結果來說雖然是有改進,但是改進的幅度並沒有很大,如果想要讓判斷特徵點的準確度有更明顯的提高,就要對程式進行較大規模且較深入的修改,對於現階段的我而言,目前還沒有能力解決此問題,這個問題要等到未來做更深入的研究之後才有可能解決。
8. 參考資料