![]()
2.1 Transformation
¦b¤ÀªR¸ê®Æªº¹Lµ{¤¤¡A¬°¤F¨Ï¤§«á¾Ç¨ìªº¸ê®Æ¯à°÷¦³·Ç½Tªº¥Nªí©Ê¡An³Q¾Çªº¸ê®Æn¦³¤@P©Ê¡A©Ò¥H¦b¾Ç¸ê®Æ¥H«e¡A§ÚÌ¥²¶·§@¤@¨Çalignmentªº°Ê§@¡A¦b³oӰʧ@¤¤¡A§ÚÌ·|±N¸ê®Æ§@transformation¡C
Transformation¤jP¤W¥i¥H¤À¦¨¤TºØÃþ«¬¡Gtranslation¡Bscaling©Mrotation¡A¦b¨BÆJ¤¤§@alignmentªº®ÉÔ¡A§Ú¥u¥Î¨ì«e±¨âÓtranslation©Mscaling¡C
©Ò¿×ªºtranslation´N¬O«ü±N¸ê®Æ§@¥²¾¡A¨C¤@Ó¯S¼xÂIªº®y¼Ð¥H¬YÂI¬°°ò·Ç¡A§@¬Û¦Pªº¦ì²¾¶q§@¦ì²¾¡A¨Ï¬Y¤@Ó³¡¦ì(¨Ò¦p»ó¦y)ªº®y¼Ð¯à°÷¦b¬Û¦Pªº®y¼Ð¤W¡C¦Óscaling¬O«ü±N¸ê®Æ§@©ñ¤jÁY¤p¡A§â°ò·ÇÂI³]¦bìÂI¡A§Q¥Îtranslation±N¸ê®Æ§@¥²¾¡A¦A±N¨C¤@Ó¯S¼xÂIªº®y¼Ð¦P®É¼¤W¤@ÓÈ¡A§Y¥i°µ¨ìµ¥¤ñ¨ÒÁY©ñªº®ÄªG¡C
§Q¥Î¥H¤W³o¨âÓ¤èªk¡A§ÚÌ¥i¥H±Nn¤ÀªRªº¸ê®ÆºÉ¶q°µ¨ì¤@P©Êªº®ÄªG¡C
2.2 ¨BÆJ
¤@¡B¨D¥XNEmean(¤£¦P¤H¶¡¡AµLªí±¡ªº¥§¡®y¼ÐÈ)
¨D¥X100µ§NE¸ê®Æ68Ó¯S¼xÂIªº¥§¡È¡A¨Ã¥B¦sÀɦ¨NE0000.log¡C
¤G¡B¹ï©Ò¦³NE§@align
¨C¤@ÓmodelªºNE¤j¤p¬Ò¤£¦P¡A¬°¤FnÅý¤§«á¤ÀªRªº¸ê®Æ¯à¦³¤@P©Ê¡A©Ò¥Hº¥ýn¥ý±N¨CÓmodelªºNE¹ïNEmean§@align¡A¨Ï©Ò¦³NEªº¤j¤p³£¯à®t¤£¦h¡C
(1) §Q¥Î²Ä38~44Ó¯S¼xÂI¨D(»ó¤l©P³ò)¥X»ó¦y¡C
(2) ¥²¾©Ò¦³¯S¼xÂI¨ÏNEªº»ó¦y®y¼Ð¯à«Å|NEmeanªº»ó¦y®y¼Ð¡C
(3) ¥H»ó¦y¬°ìÂI¡A±N©Ò¦³ªº¯S¼xÂI¥²¾¡C
(4) ¨D¥X¤@ӳ̨ÎÁY©ñÈbest_sol¡A¨Ï±o·í68Ó¯S¼xÂI¦P®É¼¥Hbest_sol¯à±o¨ì»PNEmeanªº³Ì¤p»~®t¡C
(5)±N©Ò¦³¯S¼xÂI®y¼Ð¬Ò¼¥Hbest_sol¡C
(6)¥H»ó¦y¬°°ò·Ç¡A«ì´_¥²¾«eªº®y¼Ð¡C
(7)¬ö¿ý¥B¦sÀÉ¡AÀɦW¬°ì©l©R¦W«e¥[¤Wa¡Aex¡GaNE0001.log¡C
¤T¡B¹ï©Ò¦³AN¡BDI¡BFE¡BHA¡BSA¡BSU§@global
alignment
¨Cµ§¸ê®Æªº¤j¤p¬Ò¤£¦P¡A¬°¤F¨Ï¤§«áªº¤ÀªR¯à¦³¤@P©Ê¡A©Ò¥Hº¥ýn±N¨CÓªí±¡¹ï¦Û¤vªº°Ñ¦ÒNE§@global align¡A¨ä¤¤°Ñ¦ÒNE¬°¤w§@¹Lalign«áªºNE¡C¦]¬°·í¤@Ó¤H¦b§@³o¤»ºØªí±¡ªº®ÉÔ¡A»ó¦y©M¨â²´ªºcenter¨Ã¤£·|¦³«Ü¤jªº¦ì²¾¡A©Ò¥H¦b§@alignªº®ÉÔ¡A¬O¥H³o¤TÓÂI§@¬°°ò·Ç°Ñ¦Ò¡C
(1)º¥ý¤À§O¹ïmodel¦Û¤vªº°Ñ¦ÒNEªº»ó¦y®y¼Ð§@¹ï»ô¡C
(2)¦A¥H»ó¦y¬°ìÂI§@¦ì²¾¡C
(3)§Q¥Î²Ä27~30Ó¯S¼xÂI(¥ª²´©P³ò)¨D¥X¥ª²´ªºcenter¡B²Ä32~35Ó¯S¼xÂI(¥k²´©P³ò)¨D¥X¥k²´ªºcenter¡C
(4)§Q¥Î»ó¦y¡B¥ª²´center©M¥k²´center¨D¥X¤@ӳ̨ÎÁY©ñÈbest_sol¡A¨Ïalign«á³o¤TÓ®y¼Ð¬Û¹ï©ó°Ñ¦ÒNEªº»~®tȯà³Ì¤p¡C
(5)±N©Ò¦³ªº¯S¼xÂI®y¼Ð¬Ò¼¥Hbest_sol¡C
(6)¥H»ó¦y¬°°ò·Ç¡A«ì´_¥²¾«eªº®y¼Ð¡C
(7)¬ö¿ý¨Ã¥B¦sÀÉ¡AÀɦW¬°ì©l©R¦W«e±¥[¤Wg¡Aex¡GgAN0004.log¡C
¥|¡B¨D¥Xlocal shape
deformation
·í¤@Ó¤H¦b§@³o¤»ºØªí±¡ªº®ÉÔ¡A¨äªí±¡Åܤƥi¥H¤À¦¨¨â¨BÆJ¡Aº¥ý¬O¦U³¡¦ì¹ï¦Û¤vªºcenter§@¬Û¦Pªº¦ì²¾¡A¤§«á¨CÓ¯S¼xÂI¦b§@¦U§O±o¦ì²¾(local shape
deformation)¡C©Ò¥H¤@¦@¤À¦¨¨âºØlocal shape deformation¡Gcenterªºlocal shape deformation©M©Ò¦³¯S¼xÂIªºlocal shape deformation¡C
(1)centerªºlocal shape
deformation
a.§Q¥Î²Ä15~20Ó¯S¼xÂI(¥k¬Ü©P³ò)¨D¥k¬Ücenter¡B²Ä21~26Ó¯S¼xÂI(¥ª¬Ü©P³ò)¨D¥ª¬Ücenter¡B²Ä27~30Ó¯S¼xÂI(¥ª²´©P³ò)¨D¥ª²´center¡B²Ä32~35Ó¯S¼xÂI(¥k²´©P³ò)¨D¥k²´center¡B²Ä60~65Ó¯S¼xÂI(¼L¤Ú¤º°¼©P³ò)¨D¼L¤Úcenter¡C
b.ºâ¥X³o¤Ócenter¹ï©ó°Ñ¦ÒNE¤¤ªºcenterªº¦ì²¾È¡C
c.¬ö¿ý¨Ã¥B¦sÀÉ¡AÀɦW¬°ì©l©R¦W«e±¥[¤Wc¡Aex¡GcAN0004.log¡C
(2)©Ò¦³¯S¼xÂIªºlocal
shape deformation
a.³o¤Ó³¡¦ìªº¯S¼xÂI¤À§O¹ï©ó¦Û¤vªºcenter§@¬Û¦Pªº¦ì²¾¡A¨Ï±o¦UÓ³¡¦ìªºcenter®y¼Ð¯à°÷¹ï»ô°Ñ¦ÒNEªºcenter®y¼Ð¡C
b.ºâ¥X©Ò¦³¯S¼xÂI¹ï©ó°Ñ¦ÒNEªº¦ì²¾È(local move)¡C
c.¬ö¿ý¨Ã¥B¦sÀÉ¡AÀɦW¬°ì©l©R¦W«e±¥[¤Wm¡Aex¡GmAN0004.log¡C
2.3 ¤ÀªR»PÅçÃÒ
¦b±N¦hºû¸ê®Æ¥H¸û¤Öºû¸ê®Æ¨Óªí¥Ü«e¡A§ÚÌn¥ý¨ÓÀˬd«e¥|Ó¨BÆJªº·Qªk»P§@ªk¬O§_¦³¿ù¡C§Ú©Ò±Ä¨úªº¤èªk¬O¤ñ¸ûalign«e«á¹ï©ó°Ñ¦ÒNEªº»~®tªº¥§¡È©M¼Ð·Ç®t¡A¦]¬°§@alignªº¥Øªº´N¬O¬°¤FÅýmodel©M°Ñ¦ÒNEªº»~®t¯àÅܤp¡A©Ò¥H¦pªG¥Î¦±½u¨Óªí¥Üªº¸Ü¡Aalign«eªºÂŦ⦱½uÀ³¸Ó¦balign«áªº¬õ¦â¦±½u¤W±¡C
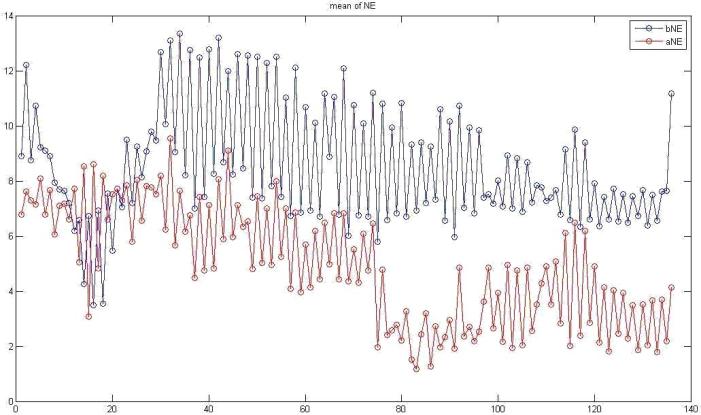
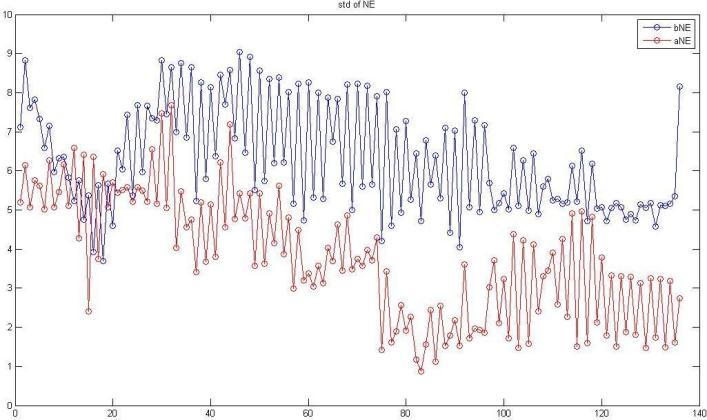
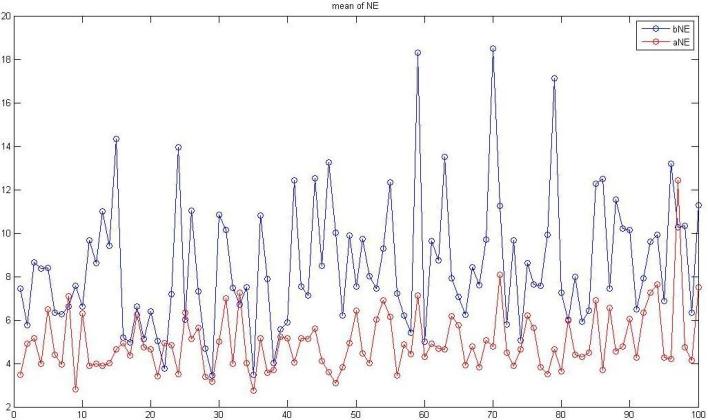
®Ú¾Ú¥H¤Wªº¤ÀªR¡A¥H¤U¬O§Ú¥h¹ê§@ªºµ²ªG¡A³£¬O¥HNE¬°¨Ò¡A¨ä¤¤¤S¤À¦¨¨âºØÅçÃÒ¡A¤@Ó¬O68Ó¯S¼xÂI¦b¬Û¦Pªí±¡¤Uªº»~®t(¤@¦@¦³136ÓÈ)¡A¥t¤@Ó¬O¤@Ó¤H¦b¤@µ§¸ê®Æ¤Uªº»~®t(¤@¦@¦³100Ó¤H)¡C
¤@¡B68Ó¯S¼xÂI
X¡G68Ó¯S¼xÂIx¡By Y¡G»~®tpixel
ÂŦ⦱½u¡G¥¼§@align«e ¬õ¦â¦±½u¡G§@¤Falign«á
¡mmean of NE¡n
¡mstd of NE¡n
¤G¡B100Ó¤H
X¡G100Ó¤Hªº½s¸¹ Y¡G68Ó¯S¼xÂI¥[Á`»~®t
ÂŦ⦱½u¡G¥¼§@align«e ¬õ¦â¦±½u¡G§@¤Falign«á
¡mmean of NE¡n
¡mstd of NE¡n
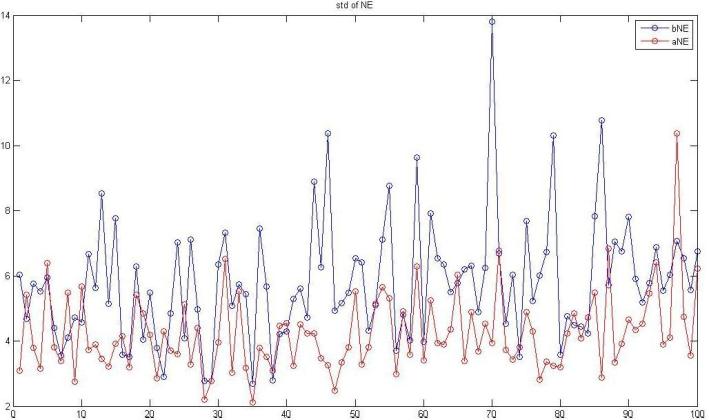
¥Ñ¥H¤Wªº¹êÅç¼Æ¾ÚÅã¥Ü¬õ¦â¦±½u´X¥G³£·|¦bÂŦ⦱½uªº¤U±¡A©Ò¥H§ÚÌ¥i¥Hª¾¹DÅçÃÒ¤èªk»P¹ê§@ªº¥¿½T©Ê¡C
2.4 PCA
¥þ¦W¬°Principal
Component Analysis¡CPCAªº·§©À¬O±N¤@Ó¦hºûªº¸ê®Æ¥i¥H¥Î¸û§Cºûªº¤è¦¡ªí¥Ü¡A§Q¥ÎPCAªº¤è¦¡¦s¨ú¸ê®Æªº¸Ü¡A¥i¥H´î¤Ö¦s¸ê®Æªº¶q¡A¦p¦¹§ÚÌ¥i¥H±N¸ê®Æ§@À£ÁY¡C
X = £g
+ ∑£\i*vi
¡A¨ä¤¤X¬OÓ¦hºûªº¸ê®Æ¡A£g¬°¸ê®Æªº¥§¡È¡Avi¬Oeigenvector¡A¨C¤@Óvi³£¬O¤@Ó¥i¥H¥Nªí³oÓ¦hºû¸ê®Æªº°Ñ¦Ò°ò·Ç¡A£\i¬O§ë¼v¨ìvi¤WªºÈ¡A¨ä¤¤i¤p©óµ¥©óXªººû«×¡Aªí¥Ü§ÚÌ¥i¥H¤£¥²¨Ï¥Î¥þ³¡ªº¸ê®Æ¡A¥i¥H§Q¥Î¤p©óµ¥©óì©l¸ê®Æªº¸ê®Æ¶q¨Ó¥N¥þ³¡ªº¸ê®Æ¡A¥t¥~eigenvector©Ò¹ïÀ³ªºeigenvalue¬Oªí¥Ü¸ê®Æ¦b³oÓ¥Nªí©Ê°Ñ¦Ò°ò·Ç¤Wªº¤À¥¬½d³ò¡C
pdm_core.mªºµ{¦¡¬OPCAªº¹Bºâ¡A§Q¥Î³oÓµ{¦¡¡A§ÚÌ¥i¥H±N¤»ºØªí±¡ªºlocal moveÂন¥Îmean¡Beigenvalue©Meigenvector¨Óªí¥Ü(¸ê®Æ¶q¸û¤Ö)¡C
2.5
¿é¥X¸ê®Æ
¸g¹Lpdm_core.mµ{¦¡ªºPCA¹Bºâ¡A§ÚÌ¥i¥H±o¨ì12Ó¿é¥X¸ê®Æ¡A¨Cµ§¸ê®Æ¤¤§t¦³eig_num¡Bmean¡Beig_val©Meig_vec³o¥|ºØ¸ê°T¡C¨ä¤¤eig_numªí¥ÜeigenvalueªºÓ¼Æ¡Ameanªí¥Ü¸ê®Æªº¥§¡È¡Aeig_valªí¥Ü¸ê®ÆªºÅܤƶq¡Aeigen_vecªí¥Ü¸ê®Æªºeigenvector¡C
¤@¡B5Ócenterªº¦ì²¾¸ê®Æ
AN_center_pdm.mat¡BDI_center_pdm.mat¡BFE_center_pdm.mat¡B
HA_center_pdm.mat¡BSA_center_pdm.mat¡BSU_center_pdm.mat¡C
¤G¡B68Ó¯S¼xÂIªº¦ì²¾¸ê®Æ