Motivation
Vehicles are common transportation nowadays, and are widely used in our daily life, for example, going to work, family trip,
picking up passengers and transporting goods, etc.
Based on the statistical data extracted from the survey relating to highway traffic flow conducted by Directorate General of Highways, M.O.T.C,
the traffic flow of major roads can be higher than 6000PCU (Passenger Car Unit) during peak hours. Due to the highly frequent usage rates,
the safety of driving becomes extremely important.
According to Ministry of Transportation Traffic Safety Committee in Taiwan, drowsy driving has always been one of the main causes of traffic accidents.
If the driver only takes less than four hours for rest, the chance of traffic accident will increase by 10 times.
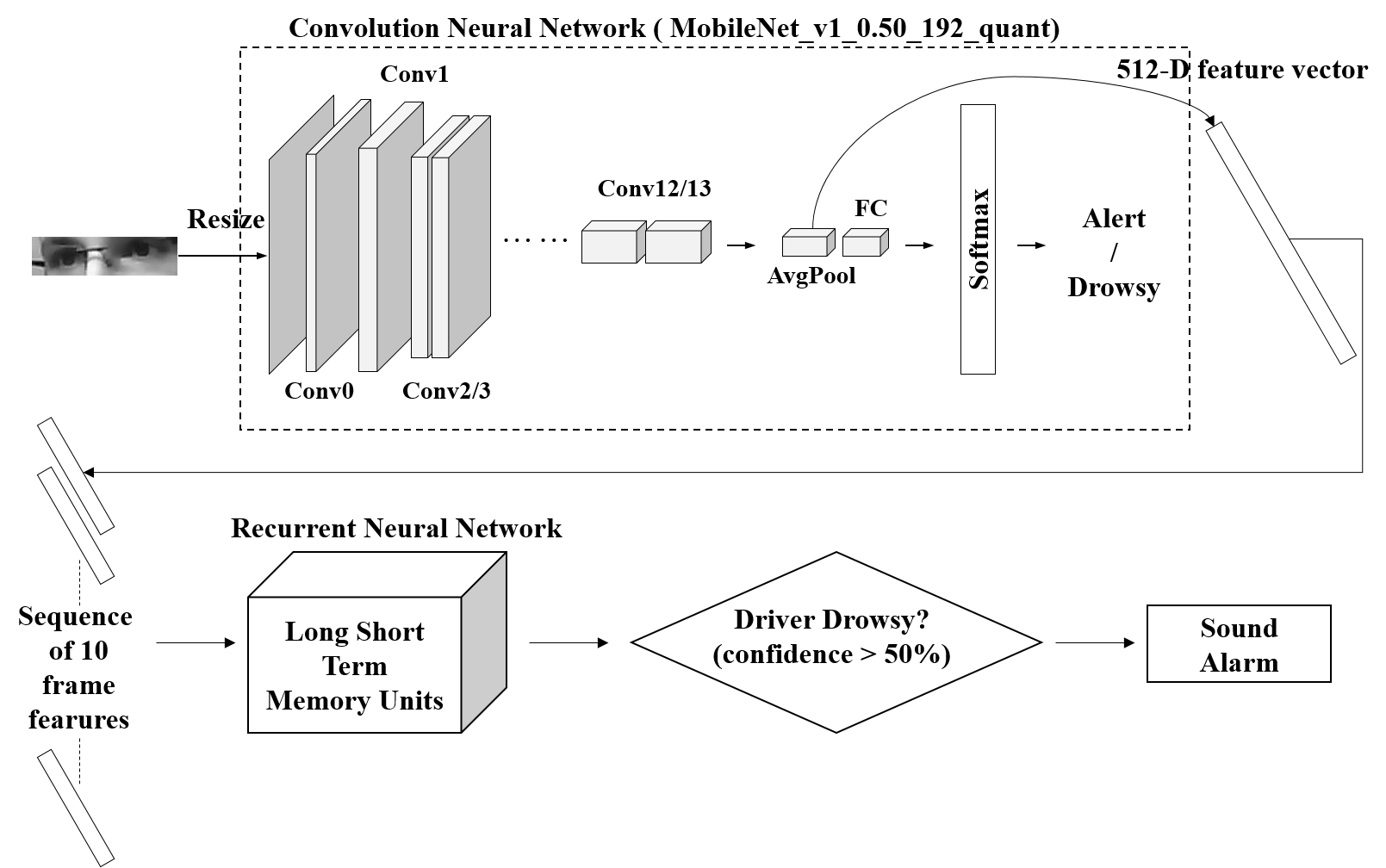
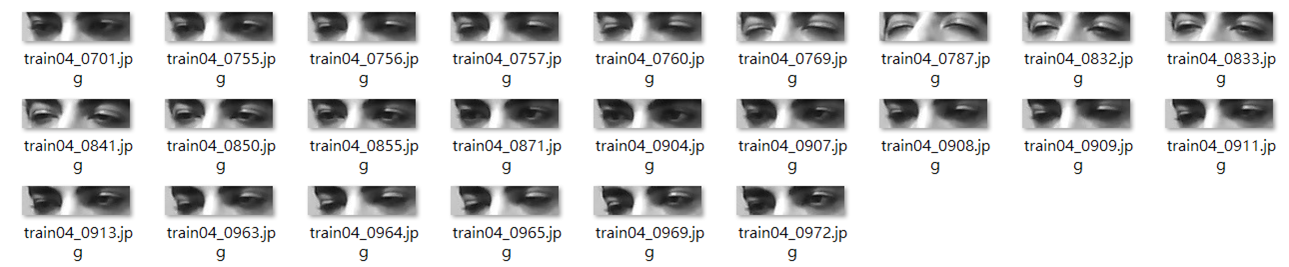
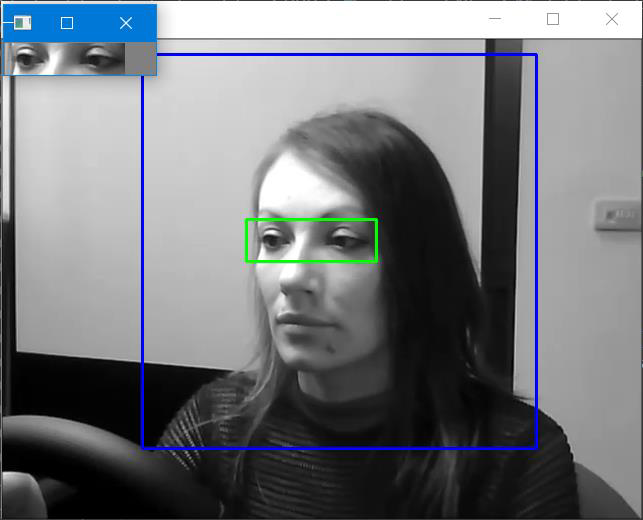
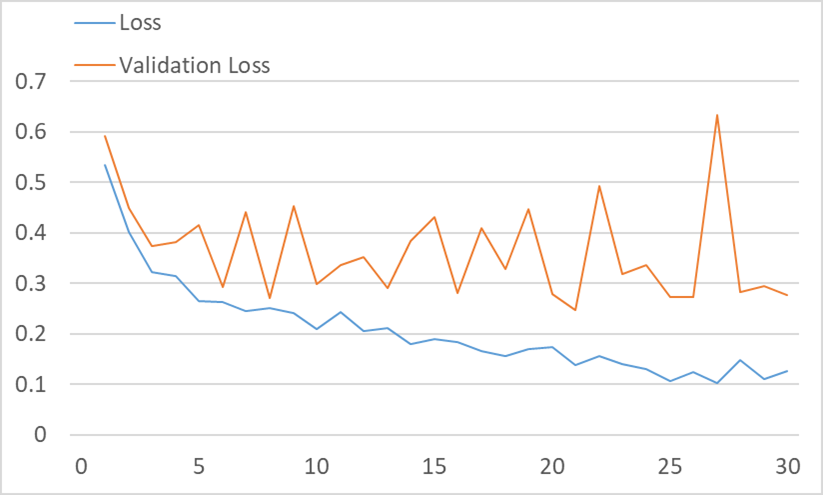
Therefore, we hope to implement a safety mechanism for drowsy driving, to prevent such incidents by raising an alarm if the driver is drowsy,
and to predict whether the driver is drowsy or not via deep learning.
learn more