A STUDY AND IMPLEMENT OF SPEECH-DRIVEN MOUTH ANIMATION BASED ON SUPPORT VECTOR REGRESSION
|
Advisee: Chih-Ming Yi
Department of Computer Science yihrichard@gmail.com.tw |
Advisor: Chia-Te Liao
Department of Computer Science dr928317@cs.nthu.edu.tw |
Advisor: Dr. Shang-Hong Lai
Department of Computer Science |
ABSTRACT
It is proved that visual mouth information could effectively help us understand the speech content. It is also keenly needed that speech signals forthrightly synthesize the corresponding face video. That is because it can observably reduce the amount of video information in transmission. In this paper, we will present a system that can deal with a input voice , then synthesizing an output mouth shape video. A deformable mouth template model is employed to parameterize the mouth shape corresponding to different transient speech signals followed by a radial basis function (RBF) interpolation technique to synthesize the mouth image according to a new set of predicted mouth shape parameters. The support vector regression (SVR) machine is used to learn the mapping from speech features to visemes, which are parameterized now by a set of mouth shape parameters. From the input speech signals, we can dynamically predict the mouth shapes through the trained SVRs and further synthesize realistic mouth images. With those synthesized mouth images, we can build a sequentially mouth shape video-playing system. Experimental results are shown to demonstrate the distinct speech-driven mouth shape video synthesis results by using the proposed algorithm.
INTRODUCTION
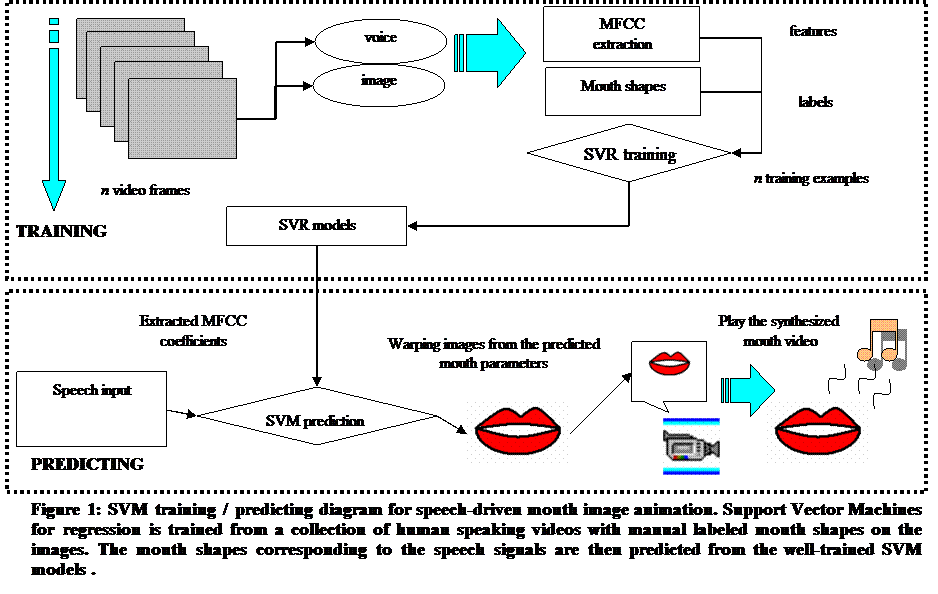
Voice-driven mouth animation system could be implement by analyze the voice and the corresponding image in the anticipatory video, and then build a related data model. After finishing this task, we can receive an input voice to synthesized the corresponding mouth shape image by combining some feature point in the synthesized image. This method could reduced lots amount of video information to output the mouth-shape image. By the method provided by Chia-Te Liao [1], we enhance the voice-driven mouth animation system. By creating and handling the serial synthesized mouth shape image, we combine all these images into a serial video.
The flowchart of this system is as the following.
SUPPORT VECTOR MACHINE
Briefly, Support Vector Machines (SVM) is a system
that seeks to optimize the generalization bounds that prevent overfitting with
the flexibility to control the complexity, while keeping consistency of the
hypotheses at the same time. Kernel tricks also provide SVM the non-linear
approximation capabilities by projecting the data into a high dimensional
feature space [2]. Given a set of training data by
![]() ,
where
,
where ![]() denotes
an example instance with
denotes
an example instance with ![]() and
and
![]() ,
and
,
and ![]() is
the total number of instances in
is
the total number of instances in ![]() .
Here,
.
Here, ![]() is
the
is
the ![]() -dimensional
input space, and
-dimensional
input space, and ![]() denotes
the output domain for the regression. We have the following optimization
function:
denotes
the output domain for the regression. We have the following optimization
function:
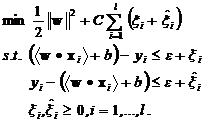 ,
(1)
,
(1)
where ![]() denotes
the weight vector,
denotes
the weight vector, ![]() and
and
![]() are
two slack variables measuring the distance upon and below the regression
function, and
are
two slack variables measuring the distance upon and below the regression
function, and ![]() is
for the penalty parameter to control the tradeoff between complexity and loss.
The objective of SVR is to determine a linear function that best interpolates
the set of examples by maximizing the margin. The nonlinear regression is
achieved in a kernel-induced feature space via a more general formulation of the
dual form. Suppose now the solution of
is
for the penalty parameter to control the tradeoff between complexity and loss.
The objective of SVR is to determine a linear function that best interpolates
the set of examples by maximizing the margin. The nonlinear regression is
achieved in a kernel-induced feature space via a more general formulation of the
dual form. Suppose now the solution of
![]() is
found. With the implicit kernel mapping
is
found. With the implicit kernel mapping
![]() ,
the prediction function
,
the prediction function![]() can
be written as
can
be written as ![]() .
(2)
.
(2)
In this case, for any speech feature vector
![]() ,
we apply the SVR prediction function
,
we apply the SVR prediction function
![]() to
predict the mouth shape parameters.
to
predict the mouth shape parameters.
THE PROPOSED METHOD
In this section we give the detailed description of the proposed speech-driven mouth animation system. As shown in Figure 1 of the system flowchart, the main goal of this work is to predict the corresponding mouth shapes from the input speech signals, and further generate video-realistic mouth images by warping from a reference mouth image with the SVR-estimated mouth shape parameters. It is reasonable to generate animated mouth images from a sequence of speech signals, thus rendering an animated video clip at the rate of 30 frames per second. For clarity of description, as depicted in the flowchart we divide the system into two separate phases in the subsequent subsections: 1) SVR training/prediction, and 2) mouth image synthesis.
3.1 SVR Training / Prediction
In order to predict the mouth shapes from the input speech signals, first we have to prepare the well-trained SVM models for regression. With the similar analogy, support vector regression seeks the maximal margin that minimizes the test errors. Compared to the traditional regression methods, it has the advantage of incorporating the kernel tricks easily, thus the power of nonlinear approximation capability can be utilized. As depicted in Fig. 1, given the prerecorded video clips of talking mouths as the training data, the learning procedure is achieved by making speech observations into the forms of training features together with the corresponding training labels of visual representations. The Mel-scale Frequency Cepstral Coefficients (MFCC) features have been shown to be very robust and reliable compared to the Linear Predictive Coefficients (LPC), and it have been more popularly used in the domain of speech recognition. In this paper, we adopt the MFCC features as the representation for transient speech signals. The MFCC feature extraction procedure can be described as follows. Firstly, for each fixed period of voice signal, Fourier Transform is applied to compute the spectrum magnitude of the input signal. Next, we apply the standard mel-filter bank analysis and take its log magnitude. Finally, with an additional
Discrete Cosine Transform (DCT), the MFCC coefficients can be computed. These filtered spectral , features now serve as the discriminative voice features for our SVR training as well as the prediction.
Next we compute the mouth
shape parameters from the corresponding mouth image as the training labels. In
this stage the deformable mouth template model, which is proposed in [3], is
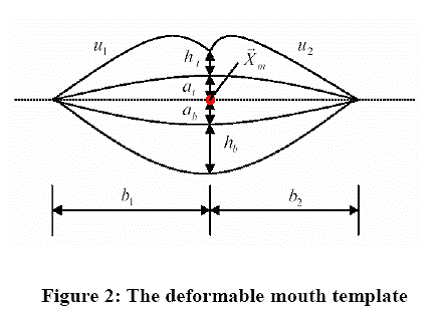
applied for our mouth shape parameterization. Figure 2 illustrates the
deformable mouth template model. Basically, this model is composed of 11
parameters![]() . In the
model, mouth is centered at the point of
. In the
model, mouth is centered at the point of
![]() with
an orientation angle
with
an orientation angle![]() . The
intersection of the two upper parabolas locates directly above
. The
intersection of the two upper parabolas locates directly above
![]() at
the height
at
the height
![]() .
The width of the mouth is the sum
.
The width of the mouth is the sum ![]() ,
where
,
where ![]() and
and ![]() are the
distances from the left and right boundaries to
are the
distances from the left and right boundaries to
![]() ,
respectively.
,
respectively.
The distance between the
two intermediate parabolas is
![]() .
We can see that from the dotted central line, the bottom parabola has a maximal
distance of
.
We can see that from the dotted central line, the bottom parabola has a maximal
distance of
![]() .
With these 11 parameters, we are able to derive five parabolas: two for the top
of the upper lips
.
With these 11 parameters, we are able to derive five parabolas: two for the top
of the upper lips ![]() and
and ![]() ,
bottom of the upper lip
,
bottom of the upper lip ![]() ,
top of the lower lip
,
top of the lower lip ![]() ,
and the bottom of the lower lip
,
and the bottom of the lower lip ![]() .
Each of the five parabolas is represented by:
.
Each of the five parabolas is represented by:
(3) (3)
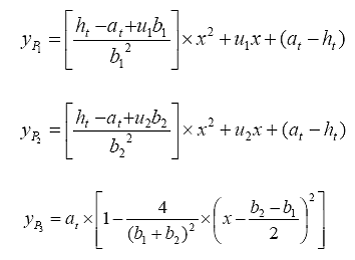
(4)
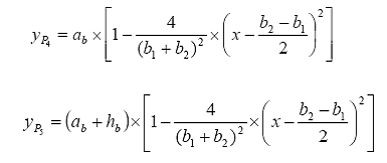
(6)
(5)
(7)
(6)
(7)
where the pair (x, y) stands for the image coordinate. Therefore, after the alignment of the mouth shapes on the collected set of data, the mouths in video frames are parameterized as the training labels. So we can train the SVR to predict mouth shapes from the MFCC features for each short-term speech observation. In our implementation, we discarded 3 parameters of center mouth location and its
orientation
![]() from
the training, since in the later warping procedure they are unnecessary given
the reference image.
from
the training, since in the later warping procedure they are unnecessary given
the reference image.
Having the trained SVM models, the next step is to synthesize the mouth image from the predicted mouth shape parameters. Mouth images corresponding to the speech signals will be generated in the following stage.
3.2 Mouth Image Synthesis
In the previous phase, we have described how to employ SVR machine to learn to predict the mouth shape parameters from the input speech signals. The next step is to synthesize the realistic mouth images based on the predicted mouth shape parameters. It has been shown that the RBF approach is very effective in multi-dimensional data interpolation for constructing a smooth parameterization of surfaces [4] [5]. In this paper, we apply the RBF technique for warping the mouth image according to the predicted mouth motion parameters. In other words, the warping transformation is an RBF function determined from a set of corresponding control point pairs, which are sampled from a silent reference mouth shape as well as the predicted one. In other words, an RBF transformation is now computed from these correspondence point pairs, and we perform the warping procedure on the source image (silent reference mouth) with the computed RBF transformation functions. Having N correspondence point pairs obtained from the SVR-predicted mouth model, the RBF interpolation is represented by a linear combination of basis functions that best fit these anchor points and is given by:
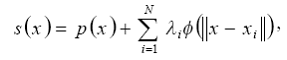 (8)
(8)
(8)
where
![]() is
the derived weight coefficients and
p(x)
is a low-order polynomial term used to resolve
the ambiguity
in RBF interpolation. Actually, we have
sampled 100
points for the RBF warping in the
experiments.
Here
is
the derived weight coefficients and
p(x)
is a low-order polynomial term used to resolve
the ambiguity
in RBF interpolation. Actually, we have
sampled 100
points for the RBF warping in the
experiments.
Here ![]() denotes
the radial basis
denotes
the radial basis
function, which is chosen
as Gaussian here in the form of
![]() ,
and
,
and ![]() denotes
the Euclidean distance. To warp a silent mouth image Σwith the mouth shape
predicted from the input speech signals, all we have to do is to label the mouth
shape of Σ by hand and further warp it with the RBF transformation computed from
the SVR-predicted mouth shape and the reference mouth shape. After performing
the
denotes
the Euclidean distance. To warp a silent mouth image Σwith the mouth shape
predicted from the input speech signals, all we have to do is to label the mouth
shape of Σ by hand and further warp it with the RBF transformation computed from
the SVR-predicted mouth shape and the reference mouth shape. After performing
the
warping operation on Σ, the mouth images consistent to the predicted mouth shapes are synthesized as the result. This is based on the assumption that human mouth shapes of similar speech features look similar.
EXPERIMENTAL RESULTS
The system interface is as the following picture:
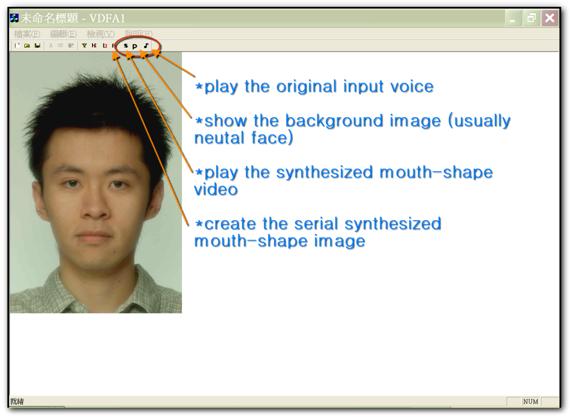
While pressing the “R” button, the system will create a
serial synthesized mouth-shape image. Then, we could press “P” button to show a
background picture, and, of course, we could change the photo as the user like.
When we press the “![]() ” button, we
could listen the original input voice which is also used to create the
synthesized image. Finally, pressing the “S” button the system will show the
mouth-shape video which is synthesized by the input voice.
” button, we
could listen the original input voice which is also used to create the
synthesized image. Finally, pressing the “S” button the system will show the
mouth-shape video which is synthesized by the input voice.
The system is running as the following picture:
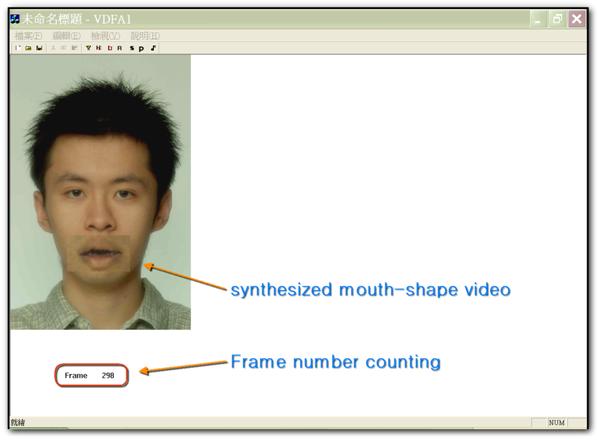
CONCLUSION
In this project, we present a realistic voice-driven mouth vedio system that combines the predicted mouth shape information and the details in photometric variation to synthesize mouth images. In the future, we intend to join the synthesized teeth and more texture details into our synthesized mouth video to make the synthesized video even real. We also plan to acquire large training and testing audio-visual data sets to test our algorithm; it might be interesting to extend this work to other shape-based animation research, such as a cartoon character retrieval system.
REFERENCE
1. Chia-Te Liao, Yu-KungWu and Shang-Hong Lai ,“Speech-driven mouth animation based on support vector regression”, Department of Computer Science
National Tsing Hua University .
2. N. Cristianini and J. S. Taylor, An Introduction to Support Vector Machines and Other Kernel-based Learning Methods, Cambridge University Press, 2000.
3. A. L. Yuille, P. W. Hallinan, and D. S. Cohen, “Feature extraction from faces using deformable
templates,” International Journal of Computer Vision, vol. 8, no. 2, 1992, pp. 99-111.
4. N. Arad, N. Dyn, D. Reisfeld, and Y. Yeshurin, “Image warping by radial basis functions: application to facial expressions,” Computer Vision, Graphics and Image Processing, vol. 56, no. 2, 1994, pp. 161-172.
5. J. C. Carr, R. K. Beatson, J.B. Cherrie, T. J. Mitchell, W. R. Fright, B. C. McCallum and T. R. Evans, “Reconstruction and representation of 3D objects with radial basis functions,” in Proceedings of ACM SIGGRAPH, Los Angeles, CA, 2001, pp. 67-76.