Introduction
Going to the gym after class or off work has becoming a trend. Usually, people hire a fitness coach to give instructions and lead people to the correct fitness pose. However, the cost of hiring a coach is large. Given that, we want to construct an end-to-end software application to be a coach for fitness needs. Our model recieves user-record clips of specific fitness poses, and our model will give the indication of correctness regarding the poses. We currently choose only shoulder press as the accepted input pose. Shoulder press is a relativty complex action, the resulting performance from the comparison model [1] (also our baseline) is poor. Our model surpasses the baseline model, showing that our model is capable to handle recognition of complex actions, compared to the hard-code algorithm in the baseline model. Recongtion for other actions should also be possible once given enough training data.
The task of human action recognition is hard, because it relies on the prior knowledge to get understanding of visual world and the human action is more sophisticated than non-human object. Therefore, instead of feeding raw video dataset in pixel by frame, our model is skeleton-based , where human skeleton conveys crucial information of the human body structure. Specificly, Spatial Temporal Graph Convolutional Networks (ST-GCN) [2], is thus adopted to our model.
We choose ST-GCN as our backbone model, functioning as a feature extractor to skeleton input data. We initialize the parameters with the well-trained parameters from the general human action recognition task. Then we train the whole model with our whole dataset using logistic regression as the final layer for classification──this step can be viewed as a form of curriculum learning to tune the backbone layers better for our application. We then discard the logistic regression layer and replace it with traditional anomaly detection algorithms, e.g., one class support vector machine. Finally, the model is trained on only positive samples, and tested on positive and negative samples.
Standing Shoulder Press Pose

Methodology
Collect our own dataset
Concerning that the dataset we currently use doesn’t provide original video. Besides, the dataset is not big enough, so we want to collect our own dataset to demonstrate our software application. Because the definition of the correct poses needs professional knowledge, we contact our P.E. teacher of NTHU to collect correct pose data and wrong pose data to construct our own dataset.
Work Flow
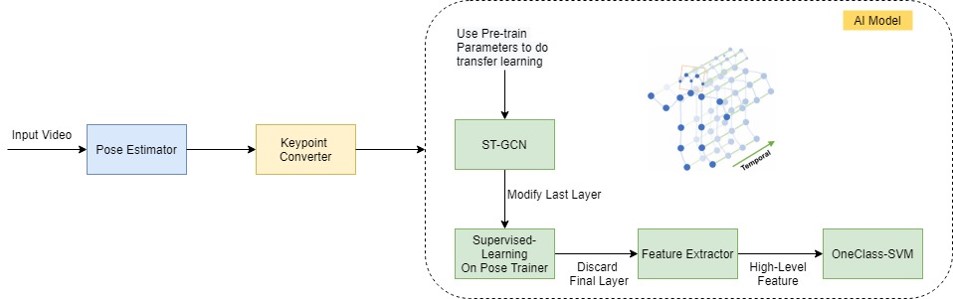
ST-GCN recieves keypoints of human joints, rather than the raw pixels. Therefore, we use the pose estimation models included in the original ST-GCN framework to convert raw pixels to keypoints. Using other pose estimation algorithms such as OpenPose is possible. ST-GCN stack multiple such GCN layers, composing a large block that takes skeleton keypoints as input, and produces high level features of action information as output. Note that after the stack of GCN layers, ST-GCN put up a global pooling to reduce the dimension into the same size, regardless of what size the video is. This makes the dimension of output consistent and reduces the impact of noise from the same type of events with different pixel sizes.
We then can regard the GCN layers as an independent feature extractor, and be free to modify the classification layer as our application needs. We choose One Class SVM as our classification layer. The justification of our choice is that, compared to the supervised algorithm of classification, anomaly detection algorithms like OCSVM focus on modeling the distribution of correct poses. This makes sense because while there are many possible incorrect fitness poses, the correct ones share similar pattern of movement.

We finally build a local web app which is connected to firebase to provide back-end storage and management. The user interface contains an upload button for user to upload the fitness pose video clip. While uploading the video, the video will be pushed to firebase storage, also the video path would be uploaded to firebase real-time database. The listener (our model) will then process the video and throw back the video with keypoints and correct/anomaly score to users.
Fine-tuning ST-GCN
The original ST-GCN is used on the general classification of human actions. We need to fine-tune the paramaters to better fit our usage. We load the parameters of the original ST-GCN model that was trained on a large-scale open dataset, Kinetics Human Action Video Dataset, which is attched in the github [3] of the original paper. The dataset is about the classification of 400 types of human actions. In spite of different domain of applications, the original parameters still represent the high-level features of general human actions. Initializing with those parameters gives us a good start to further learn the features of fitness videos. Then we aim to fine-tune ST-GCN model. We train the pretained model on our dataset, then discard the final layer to replace it with OCSVM. The backbone layers of ST-GCN get the fine-tuned domain-specifc parameters, and thus can better capture the high features we want.
Experiment
We use the results from Pose Trainer as out base line. Especially, shoulder press results in the worst performance in Pose Trainer, and thus shoulder press is our primary training goal. We train and test on Pose Trainer dataset and our dataset separately. The train test split strategy is we split one third of the positive samples and all negative samples to testing set, and the remaining two third of positive samples are used as training set. The results are as follow:
Experiment
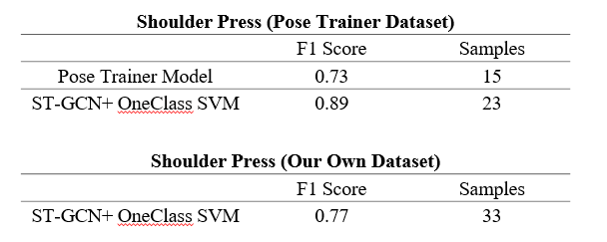
We can see that compared to the Pose Trainer model, our model performs better, regardless of which dataset are used. This is because our model exploit the representation power of deep learning model, and we use anomaly detection algorithm as our classification algorithm, which fits the task better.
Also, test results using Pose Trainer on our dataset, are all considered incorrect poses. Even there is a pose done by our PE teacher, Pose Trainer still somehow says the pose is not correct. Considering Pose Trainer only calculates the angle between each part of body torso, and the standard of "correctness" is hard coded by some particular numbers, we suspect that it is more likely that Pose Trainer fails to generalize.
Conclusion
We build an end-to-end application to assist people correct their fitness pose. In the beginning, we use the dataset of Post Trainer, and we test our model on it to compare the performance of our model. We found that our ST-GCN model surpasses. To further inpect the performance of our model, we also collected our own dataset. Seeing that our model still generalize over another dataset, we conclude the success is due to the power of deep learning networks, and the suitable problem representation of human action recognition.
It is still obvoius that both datasets are too small to convince others that the performance of our models can be well-generalized, if considered in a more rigorous sense. However, given that the nature of our task is highly related to commercial usage, large open source dataset may be not attainable. During the process of collecting our own dataset, we visited the PE teacher of NTHU who is professional in this area and asked for assistance. The teacher told us how to differentiate the correctess or incorrect parts of shoulder press poses. While we were able to perform the supposed "correct" poses, we also see that the supposed "correctess" has different degree of details that are can result in ambigular standards even in human sense. More discussion and researches regarding those ambigularity are expected in the future work.
Nonetheless, we represent a framework of recognizing sophisticated human action, utilizing the power of deep learning detworks. Also we build an end-to-end application, using web app to connect the user interface and the usage of our model. The end-to-end design provides users with no programming background the access of our model.
Reference
[1] Steven Chen, Richard R. Yang, (Sun, 21 Jun 2020), Pose Trainer: Correcting Exercise Posture using Pose Estimation
[2] Sijie Yan et al., (Thu, 25 Jan 2018), Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
[3] Github codes of [2]: https://github.com/open-mmlab/mmskeleton