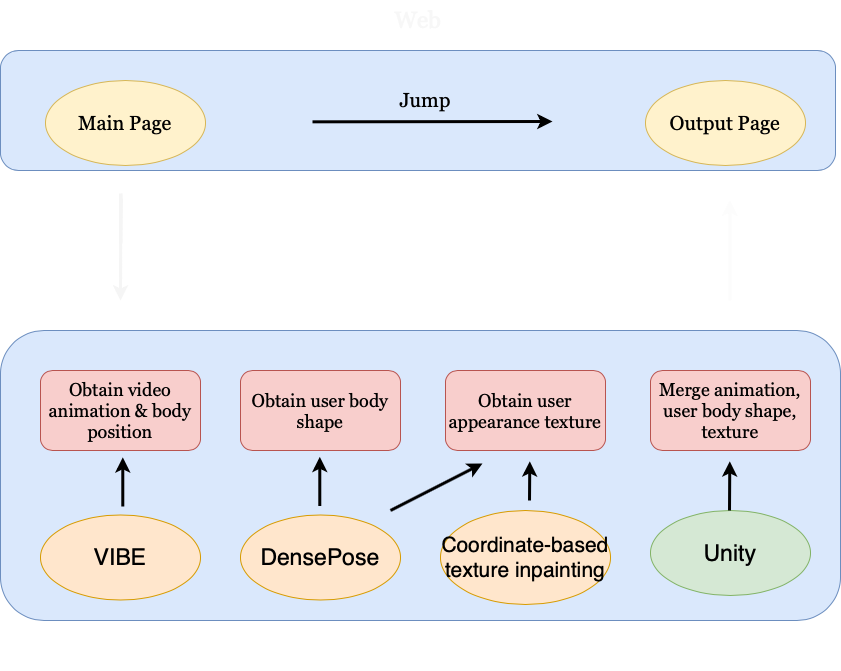
Models We Used
VIBE [1]
Given a video, this model produces 3D body pose, position, and shape parameters. This model can convert these parameters to SMPL human model. An adversarial learning framework is applied to discriminate between real humans and the predicted ones.
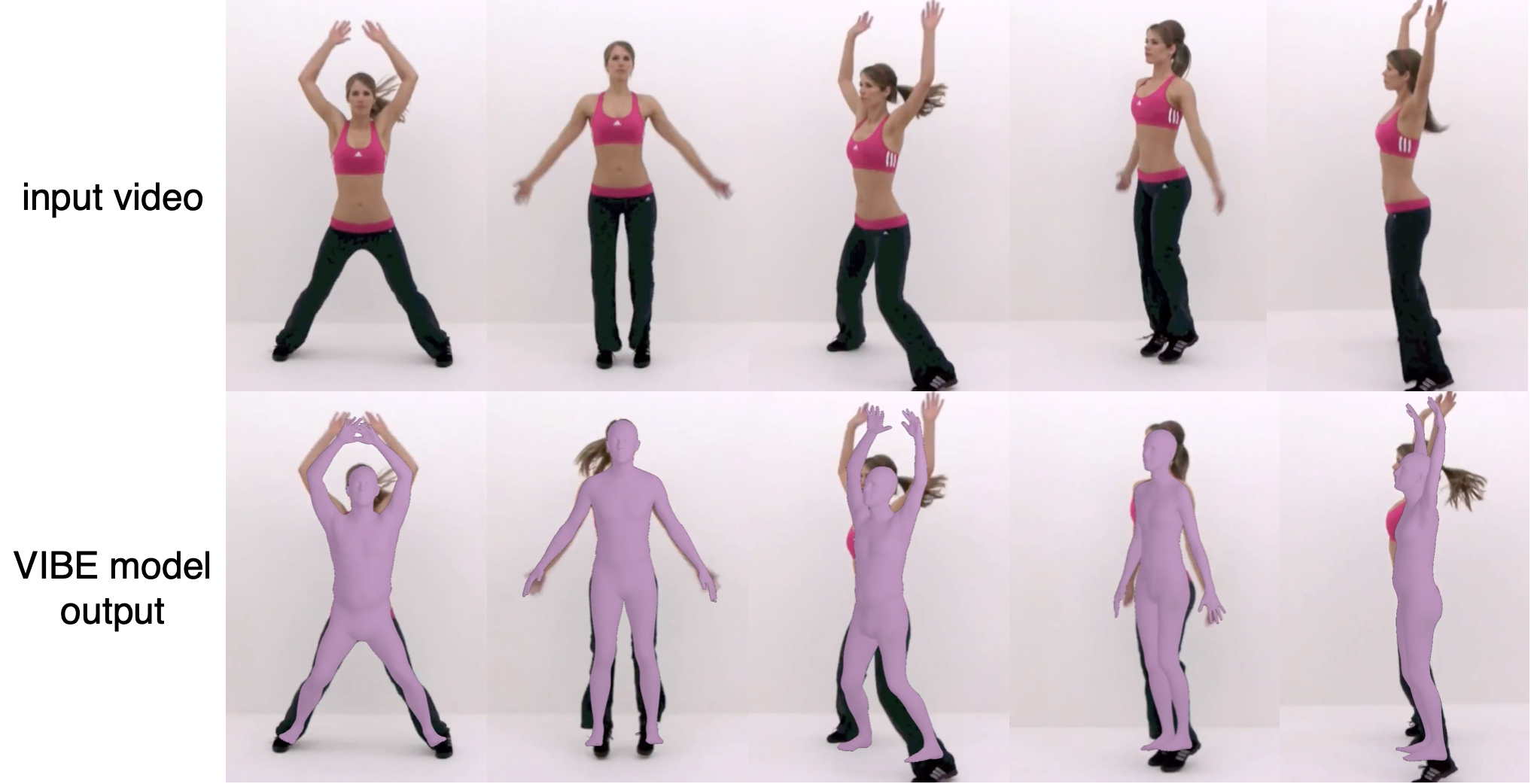
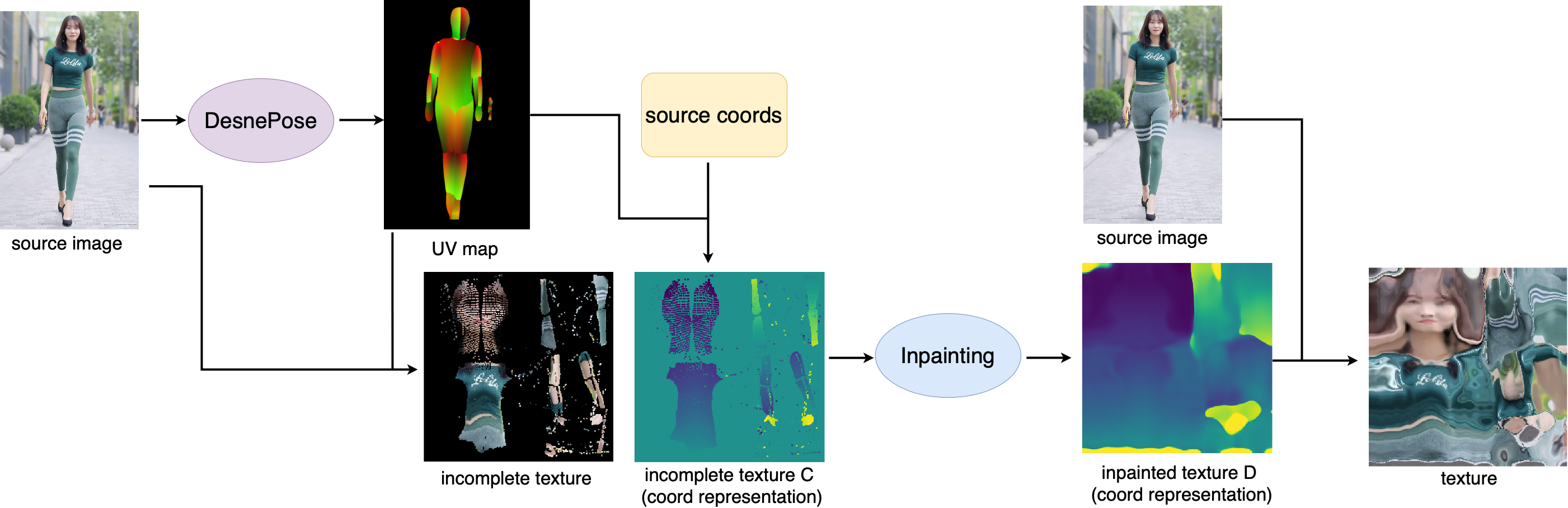
DensePose & Coordinate-based texture inpainting [2][3]
These two models process body texture. DensePose classifies and regresses every pixel in user image into U, V coordinates. The resulting texture is incomplete due to limited information about the back body. Coordinate-based texture inpainting model takes UV map and source image as input. It predicts the remaining body texture and samples colors from the source image. We apply these two models to obtain SMPL texture.
Reference:
[1] Muhammed Kocabas, Nikos Athanasiou, Michael J. Black. VIBE: Video Inference for Human Body Pose and Shape Estimation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Dec 2020.
[2] Riza Alp Gu ̈ler, Natalia Neverova, and Iasonas Kokkinos. DensePose: Dense human pose estimation in the wild. In The IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), June 2018.
[3] Artur Grigorev, Artem Sevastopolsky, Alexander Vakhitov, Victor Lempitsky. Coordinate-based Texture Inpainting for Pose-Guided Image Generation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, July 2019.
Given a video, this model produces 3D body pose, position, and shape parameters. This model can convert these parameters to SMPL human model. An adversarial learning framework is applied to discriminate between real humans and the predicted ones.
DensePose & Coordinate-based texture inpainting [2][3]
These two models process body texture. DensePose classifies and regresses every pixel in user image into U, V coordinates. The resulting texture is incomplete due to limited information about the back body. Coordinate-based texture inpainting model takes UV map and source image as input. It predicts the remaining body texture and samples colors from the source image. We apply these two models to obtain SMPL texture.
Reference:
[1] Muhammed Kocabas, Nikos Athanasiou, Michael J. Black. VIBE: Video Inference for Human Body Pose and Shape Estimation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Dec 2020.
[2] Riza Alp Gu ̈ler, Natalia Neverova, and Iasonas Kokkinos. DensePose: Dense human pose estimation in the wild. In The IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), June 2018.
[3] Artur Grigorev, Artem Sevastopolsky, Alexander Vakhitov, Victor Lempitsky. Coordinate-based Texture Inpainting for Pose-Guided Image Generation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, July 2019.