Work Flow
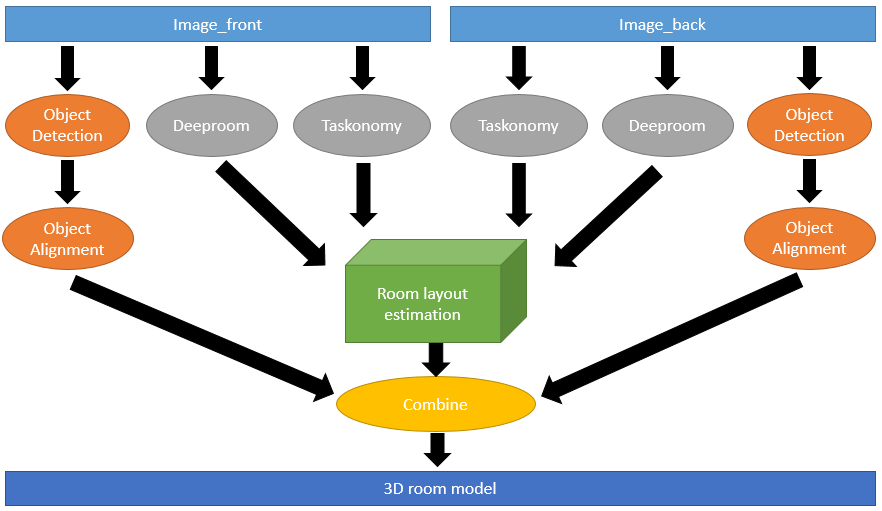
1. 以 RGB 相機(例如手機)在房間內拍攝兩張 2D 照片(分別是Image_front 和 Image_back)。
2. 我們首先使用 Taskonomy 找出 camera 的一些資訊,我們假設一個虛擬的三維空間,而 camera 所在的位置在此空間系的( 0, 0, -1 ),User 的視線則是指向正 Z 軸,那我們想要的資訊就是 camera 的拍攝角度,因為有可能會跟 User 視線有些許偏差,加上這個偏差可以讓還原出來的 3D 模型更加擬真。
3. 再來我們使用 DeepRoom,這個 model 能夠找出在照片中房間的牆角(corner)位置、牆邊(edge)長度,有了牆角的位置,可以透過實際的房間大小找出圖片當中 pixel 與 pixel 之間對應的實際距離,接著我們就可以在之後使用一些相似形的方法找出 object 在房間當中的位置。
4. 接著一樣使用兩張原圖,利用現有 trained 好的 Faster RCNN model,分別對其做 Object Detection 後,記錄下每個 object 的 bounding box 位置,之後會根據此決定每個 object 在空間中的 2D 資訊,同時用人工標記出兩張照片中重複出現的物體,將重複的物體依照 object detection 時算出的機率去篩選,留下機率較高者。
5. 知道有哪些object後,分別對每個 object 做 Object Alignment,利用 Seeing3Dchairs 這篇論文的方法,從大量現有的 3D 模型中計算配對出跟我們的 object 最相近的模型。
6. 兩張圖片分別根據第二步當中算出的相機與其對應牆壁位置,以及第三步 object 的 bounding box 位置,搭配實際的房間及物件大小,利用相似形概念,算出 object 在房間中的位置,並將之擺入,即完成整體房間 3D 重建。