Weird Result in FPS
Why FPS gets lower mIOU than random sampling, while FPS gets more average in data sampling?
Our Assumption: Although FPS has more average result, the coverage is too similar in every epoch.
Let's take a point cloud as example:
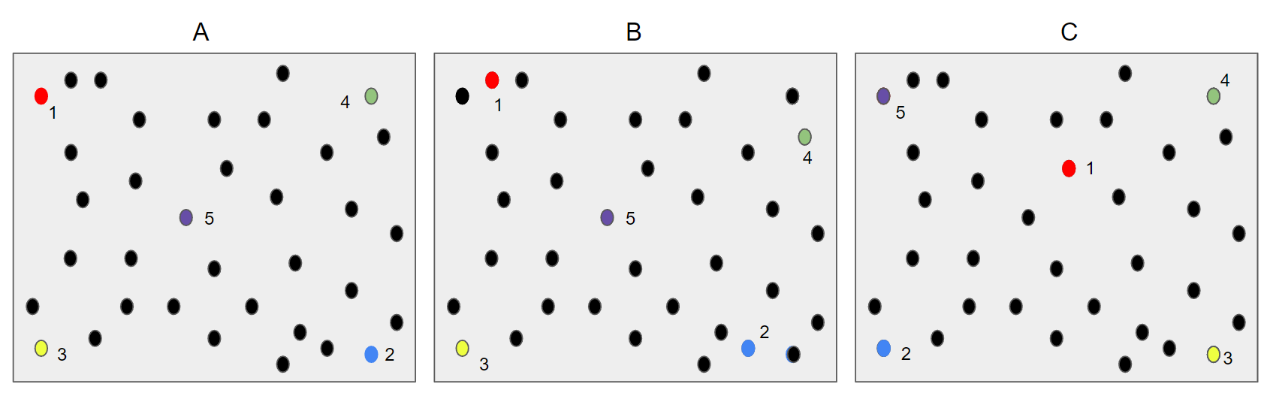
The three point cloud A, B, and C in the above figure are the same point cloud.
And the sampling order is that first randomly selected point (Red), then according to the order of the farthest point sampling blue → yellow → green → purple, point cloud A is similar to the first point sampled by point cloud B, and the first point sampled by point cloud C is the center.
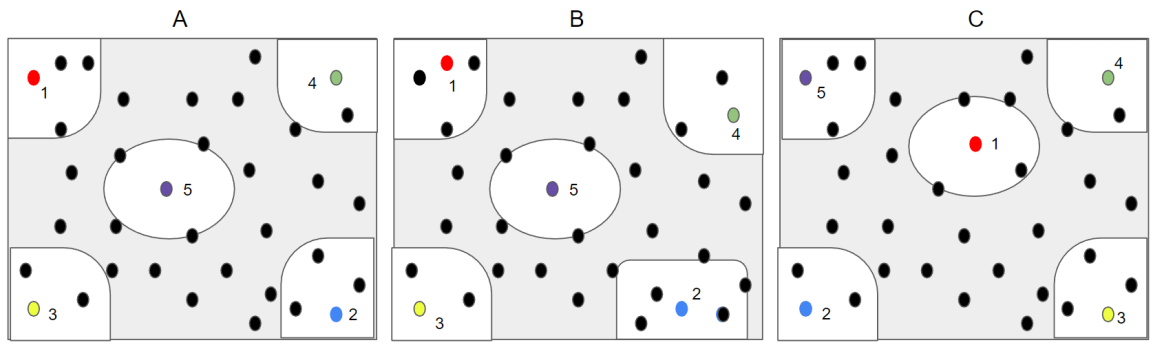
As can be seen from the above figure, after the three FPS of the point cloud are completely different, the final result after finding the nearest 30,000 points to the sampling point, the obtained data (the white bottom part) are very similar.
All of which are the four corners and the center part. This makes the coverage of different epochs too similar, and when the number of samples of the large point cloud is too small, the part with the gray background can never be obtained, which also causes dead ends.
Compared with random sampling, it is more likely to obtain the gray part that cannot be obtained by the FPS, so random sampling can achieve better performance in the case of limited resources.


