- Facial Expression Analysis
- Gesture Recognition
- Face Recognition
- Image Classification
- Object Detection
- Object Tracking
- Semantic Segmentation
- Action Recognition
- Style Transfer
- Image Restoration
- Image Alignment
Facial Expression Analysis
| Tue, 24 Jul 2018 - intern_james | |
| Driver drowsiness detection via a hierarchical temporal deep belief network | |
| C.-H. Weng, Y.-H. Lai, S.-H. Lai | |
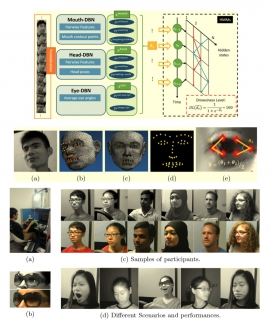
| Drowsy driver alert systems have been developed to minimize and prevent car accidents. Existing vision-based systems are usually restricted to using visual cues, depend on tedious parameter tuning, or cannot work under general conditions. One additional crucial issue is the lack of public datasets that can be used to evaluate the performance of different methods. In this paper, we introduce a novel hierarchical temporal Deep Belief Network (HTDBN) method for drowsy detection. Our scheme first extracts high-level facial and head feature representations and then use them to recognize drowsiness-related symptoms. Two continuous-hidden Markov models are constructed on top of the DBNs. These are used to model and capture the interactive relations between eyes, mouth and head motions. We also collect a large comprehensive dataset containing various ethnicities, genders, lighting conditions and driving scenarios in pursuit of wide variations of driver videos. Experimental results demonstrate the feasibility of the proposed HTDBN framework in detecting drowsiness based on different visual cues. | |
| test.php | (test.php) |
| Tue, 24 Jul 2018 - intern_james | |
| Novel Facial Expression Recognition by Combining Action Unit Detection with Sparse Representation Classification | |
| Te-Feng Su, Ching-Hua Weng, Shang-Hong Lai | |
| This paper presents a multi-attribute sparse coding approach for facial expression recognition by regarding Action-Units (AUs) as attributes. AUs describe the movements of individual facial muscles, which are detected from corresponding attribute masks in this work. They can not only be used to de scribe group property which enforces basis selection from groups with the same AUs as best as possible, but also penalize the selection of atoms with the AU distance far away from the target instance. The group constraint and the AU similarity constraint are incorporated into the formulation of l1-minimization to determine the optimal sparse representation for facial expression. Finally, we demonstrate the proposed algorithm through experiments on two facial expression datasets to show the effectiveness and robustness of the proposed method. |

| Mon, 23 Jul 2018 - intern_james | |
| Multi-attribute sparse representation with group constraints for face recognition under different variations | |
| C.K. Chiang, T. F. Su, C. Yen and S. H. Lai | |
| A novel multi-attribute sparse representation enforced with group constraints is proposed in this paper. Data with multiple attributes can be represented by individual binary matrices to indicate the group properties for each data sample. Then, these attribute matrices are incorporated into the formulation of l1-minimization. The solution is obtained by jointly considering the data reconstruction error, the sparsity property as well as the group constraints, thus making the basis selection in sparse coding more efficient in term of accuracy. The proposed optimization formulation with group constraints is simple yet very efficient for classification problems with multiple attributes. In addition, it can be derived into a modified sparse coding form so that any l1-minimization solver can be employed in the corresponding optimization problem. We demonstrate the performance of the proposed multi-attribute sparse representation algorithm through experiments on face recognition with different kinds of variations. Experimental results show that the proposed method is very competitive compared to the state-of-the-art methods. |
| Fri, 20 Jul 2018 - intern_james | |
| Learning expression kernels for facial expression intensity estimation | |
| C.-T. Liao, H.-J. Chuang, S.-H. Lai | |
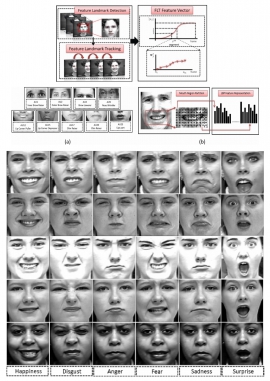
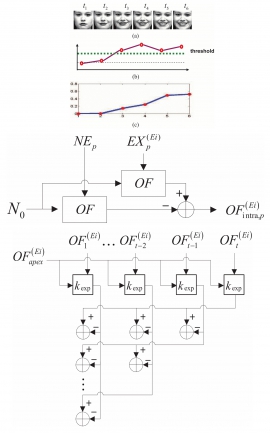
| Although many studies of facial expression analysis have been conducted, most previous works indeed focused on expression recognition. Different from previous works, this paper proposes a novel approach to learn the expression kernel for facial expression intensity estimation. The solution involves first aligning the optical flow to a neutral face to reduce inter-person variations in facial geometry, followed by solving an optimization problem with the ordinal ranking of expression intensities in temporal domain as constraints. Extensive experiments on the Cohn-Kanade database manifest that using the learned expression kernels leads to superior performance than the previous methods for facial expression intensity estimation. |
| Fri, 26 Nov 2010 - deef | |
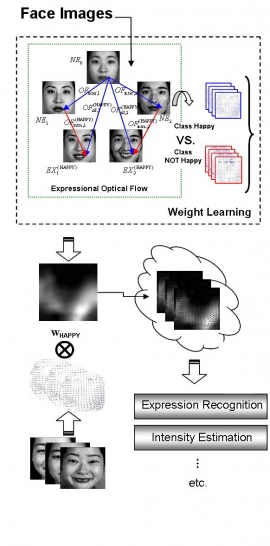
| Learning Spatial Weighting for Facial Expression Analysis by Constrained Optimization | |
| C.-T. Liao, H.-J. Chuang, C.-H. Duan, and S.-H. Lai | |
| Facial expression analysis is essential for human-computer interface (HCI). For different expressions, different parts of the face play different roles with the distinct movement of facial muscles. In this work, we propose to learn the weight associated with different facial regions for different expressions. The facial feature points are first located accurately based on a graphical model. Based on using the constrained optical flow to represent the facial motion information due to expression, a quadratic programming problem is formulated to learn the optimal spatial weighting from training data such that face images of the same expression category are closer than those of different categories in the weighted optical flow space. We demonstrate the advantages of applying the learned weight to facial expression recognition and intensity estimation through experiments on several well-known facial expression databases. |
Gesture Recognition
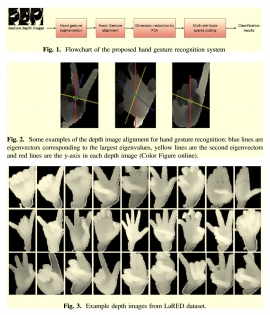
| Tue, 24 Jul 2018 - intern_james | |
| Sparse Representation Based Approach for RGB-D Hand Gesture Recognition | |
| Te-Feng Su, Chin-Yun Fan, Meng-Hsuan Lin, and Shang-Hong Lai, | |
| In this paper, we present a new algorithm for RGB-D hand gesture recognition by using multi-attribute sparse representation enforced with group constraints. Firstly, the hand region is segmented from the background according to the depth information. Then, we process all gesture-performing hand region images with PCA to reduce the feature dimension. To obtain a more accurate and discriminative representation, a multi-attribute sparse representation is employed for hand gesture recognition from different view angles. The multiple attributes for a gesture image can be represented by individual binary matrices to indicate the group properties for each gesture. Then, these attribute matrices are incorporated into the formulation of l1-minimization in the sparse coding framework. Finally, the effectiveness and robustness of the proposed method are demonstrated through experiments on a public RGB-D hand gesture dataset |
Face Recognition
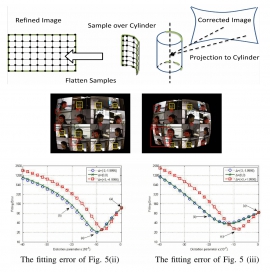
| Tue, 24 Jul 2018 - intern_james | |
| Correcting radial and perspective distortion by using face shape information | |
| Tung-Ying Lee, Tzu-Shan Chang, and Shang-Hong Lai | |
| In this paper, we propose a new technique for compensating radial and perspective distortions of photos acquired with wide-angle lens by using facial features detected from the images without using predefined calibration patterns. The proposed algorithm utilizes a statistical facial feature model to recover radial distortion and the facial features are further used for adaptive cylindrical projection which will reduce perspective distortion near the image boundary. Our algorithm has several advantages over the traditional methods. First, traditional calibration patterns, like man-made straight buildings, chessboards, or calibration cubes, are not required in our method. Even though the radial distortion can be corrected by several conventional methods, most of them usually produce photos with larger perspective distortion for faces compared to our method. The system is composed of four components: offline training of the statistical facial feature model, feature point extraction from distorted faces, estimation of radial distortion parameters and compensation of radial distortion, and adaptive cylindrical projection. In order to estimate the distortion parameters, we propose an energy considering the fitness between the undistorted coordinates of the facial feature points extracted from the input distorted image and the learned statistical facial feature model. Given the distortion parameters, the fitness is calculated by solving a linear least squares system. The distortion parameters that minimize the cost function are searched in a hierarchical manner. Experimental results demonstrate the distortion reduction in the corrected images by using the proposed method. |
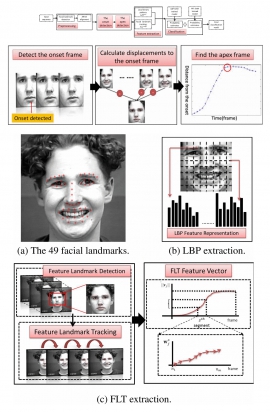
| Tue, 24 Jul 2018 - intern_james | |
| Online facial expression recognition based on combining texture and geometric information | |
| Ching-Hua Weng, Shang-Hong Lai, Michel Sarkis | |
| Automatic facial expression recognition is a challenging problem in human-computer interaction. In this paper, we develop an online facial expression recognition system based on utilizing texture and motion features extracted from a video. The combination of both types of features capture static and dynamic facial information which enhances the recognition accuracy. In addition, our method is capable of automatically detecting both the onset and the apex of the expression of a face from a video. Our proposed expression recognition system is fully automatic and achieves superior performance compared to other state-of-the-art algorithms. |
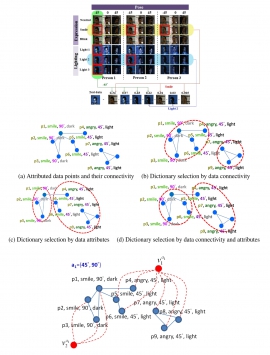
| Mon, 23 Jul 2018 - intern_james | |
| Multi-attributed Dictionary Learning for Sparse Coding | |
| Chen-Kuo Chiang, Te-Feng Su, Yen Chih and Shang-Hong Lai | |
| We present a multi-attributed dictionary learning algorithm for sparse coding. Considering training samples with multiple attributes, a new distance matrix is proposed by jointly incorporating data and attribute similarities. Then, an objective function is presented to learn category-dependent dictionaries that are compact (closeness of dictionary atoms based on data distance and attribute similarity), reconstructive (low reconstruction error with correct dictionary) and label-consistent (encouraging the labels of dictionary atoms to be similar). We have demonstrated our algorithm on action classification and face recognition tasks on several publicly available datasets. Experimental results with improved performance over previous dictionary learning methods are shown to validate the effectiveness of the proposed algorithm. |
Image Classification
| Wed, 25 Jul 2018 - intern_james | |
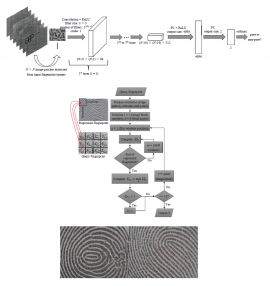
| A deep learning approach towards pore extraction for high-resolution fingerprint recognition | |
| H.-R. Su, K.-Y. Chen, W. J. Wong, S.-H. Lai | |
| As high-resolution fingerprint images are becoming more common, the pores have been found to be one of the promising candidates in improving the performance of automated fingerprint identification systems (AFIS). This paper proposes a deep learning approach towards pore extraction. It exploits the feature learning and classification capability of convolutional neural networks (CNNs) to detect pores on fingerprints. Besides, this paper also presents a unique affine Fourier moment-matching (AFMM) method of matching and fusing the scores obtained for three different fingerprint features to deal with both local and global linear distortions. Combining the two aforementioned contributions, an EER of 3.66% can be observed from the experimental results. |
| Tue, 24 Jul 2018 - intern_james | |
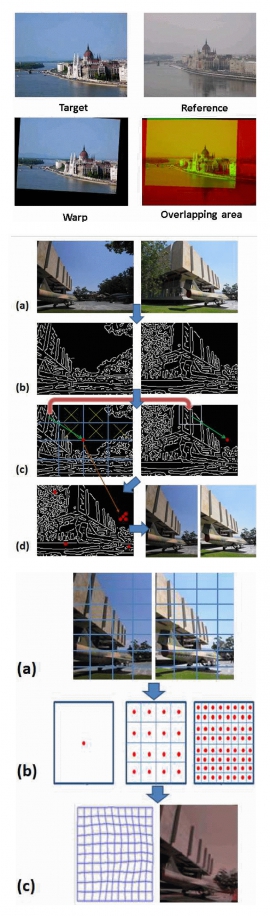
| Non-rigid Registration of Images with Geometric and Photometric Deformation by Using Local Affine Fourier-Moment Matching | |
| Hong-Ren Su, Shang-Hong Lai | |
| Registration between images taken with different cameras, from different viewpoints or under different lighting conditions is a challenging problem. It needs to solve not only the geometric registration problem but also the photometric matching problem. In this paper, we propose to estimate the integrated geometric and photometric transformations between two images based on a local affine Fourier-moment matching framework, which is developed to achieve deformable registration. We combine the local Fourier moment constraints with the smoothness constraints to determine the local affine transforms in a hierarchal block model. Our experimental results on registering some real images related by large color and geometric transformations show the proposed registration algorithm provides superior image registration results compared to the state-of-the-art image registration methods. |
| Mon, 23 Jul 2018 - intern_james | |
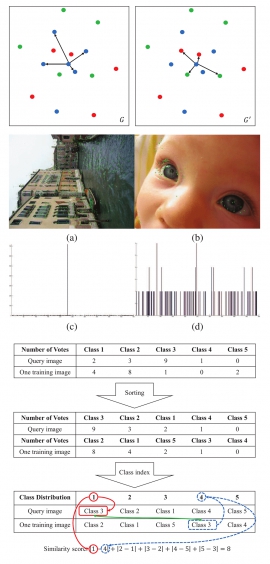
| Negative-voting and class ranking based on local discriminant embedding for image retrieval | |
| Mei-Huei Lin, Chen-Kuo Chiang and Shang-Hong Lai | |
| In this paper, we propose a novel image retrieval system by using negative-voting and class ranking schemes to find similar images for a query image. In our approach, the image features are projected onto a new feature space that maximizes the precision of image retrieval. The system involves learning a projection matrix for local discriminant embedding, generating class ordering distribution from a negative-voting scheme, and providing image ranking based on class ranking comparison. The evaluation of mean average precision (mAP) on the Holidays dataset shows that the proposed system outperforms the existing retrieval systems. Our methodology significantly improves the image retrieval accuracy by combining the idea of negative-voting and class ranking under the local discriminant embedding framework. |
| Thu, 19 Jul 2018 - intern_james | |
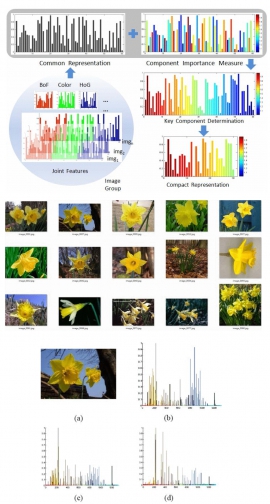
| Learning component-level sparse representation using histogram information for image classification | |
| C.-K. Chiang, C.-H. Duan, S.-H. Lai and S.-F. Chang | |
| A novel component-level dictionary learning framework which exploits image group characteristics within sparse coding is introduced in this work. Unlike previous methods, which select the dictionaries that best reconstruct the data, we present an energy minimization formulation that jointly optimizes the learning of both sparse dictionary and component level importance within one unified framework to give a discriminative representation for image groups. The importance measures how well each feature component represents the image group property with the dictionary by using histogram information. Then, dictionaries are updated iteratively to reduce the influence of unimportant components, thus refining the sparse representation for each image group. In the end, by keeping the top K important components, a compact representation is derived for the sparse coding dictionary. Experimental results on several public datasets are shown to demonstrate the superior performance of the proposed algorithm compared to the-state-of-the-art methods. |
Object Detection
Object Tracking
Semantic Segmentation
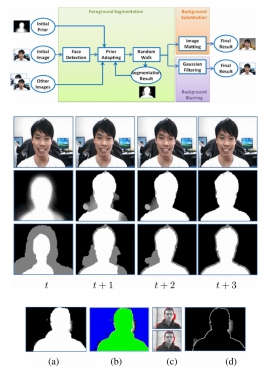
| Mon, 23 Jul 2018 - intern_james | |
| Human segmentation from video by combining random walks with human shape prior adaption | |
| Y.-T. Lee, T.-F. Su, H.-R. Su, S.-H. Lai, T.-C. Lee and M.-Y. Shih | |
| In this paper, we propose an automatic human segmentation algorithm for video conferencing applications. Since humans are the principal subject in these videos, the proposed framework is based on human shape clues to separate humans from complex background and replace or blur the background for immersive communication. We first detect face position and size, track human boundary across frames, and propagate the segmentation likelihood to the next frame for obtaining the trimap to be used as input to the Random Walk algorithm. In addition, we also include gradient magnitude in edge weight to enhance the Random Walk segmentation results. Finally, we demonstrate experimental results on several image sequences to show the effectiveness and robustness of the proposed method. |
Action Recognition
Style Transfer
Image Restoration
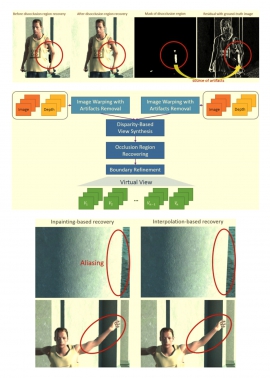
| Tue, 24 Jul 2018 - intern_james | |
| Hierarchical Interpolation-Based Disocclusion Region Recovery for Two-View to N-View Conversion System | |
| W.-T. Lin, C.-T. Yeh, and S.-H. Lai, | |
| In this paper, we propose a novel disocclusion region recovery approach for two-view to n-view conversion system. Although the topic of view synthesis has been exhaustively studied for decades, a reliable disocclusion region recovery approach, an indispensable issue in synthesizing realistic content of virtual view, is still under research. The most common concept used for predicting these unknown pixels is inpainting-related method, which fills the disocclusion region with the information of mated exemplars in self-defined searching domain. In spite of widely taken in making up the missing values generated among the synthesis procedures, the result quality of inpainting-based approach is sensitive to the filling priority and also unstable in recovering large disocclusion region. Therefore, we propose a hierarchical interpolation-based approach to calculate the desired lost information under coarse-to-fine manner accompanied with the joint bilateral upsampling technology, applied for enlarging the estimation from small dimension to higher-resolution. Proposed hierarchical interpolation-based scheme is more robust in restoring the value of missing region and also induces fewer artifacts. We demonstrate the superior quality of the synthesized virtual views under the proposed recovery algorithm over the traditional inpainting-based method through experiments on several benchmarking video datasets. |
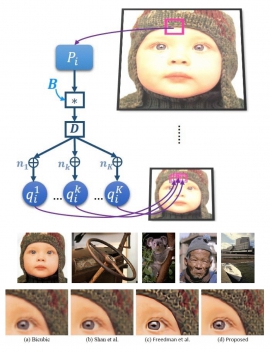
| Mon, 23 Jul 2018 - intern_james | |
| Single Image Super-Resolution Based on Local Self-Similarity | |
| W.-T. Lin and S.-H. Lai | |
| Single image super-resolution, namely increasing the resolution from only one coarse-resolution image, is a fundamental problem in computer vision. Although it has been extensively studied for decades, super-resolving a real-world image still remains challenging. In this paper, we propose a novel approach for image super-resolution by exploiting local self-similarity. First, we take advantage of this property by binding several similar patches found in a limited window into a group. Then, a novel super resolution technique is applied in the patch-based manner along with the classical reconstruction-based framework by replacing the required multiple inputs with the aforementioned group, which consists of numerous similar patches and holds the vital registration information required in the super-resolution. Experimental results demonstrate the high quality of proposed algorithm through objective DIIVINE index score as well as the subjective user study evaluation. Both ways of evaluation strongly support that the proposed single-image super-resolution algorithm is competitive and provides satisfactory results. |
Image Alignment

| Mon, 23 Jul 2018 - intern_james | |
| Fast image alignment with Fourier moment matching on GPU | |
| H.-R. Su, H.-Y. Kuo, S.-H. Lai and C.-C. Wu | |
| In this paper, we develop a fast and accurate image alignment system which can be applied to image sequences in real time. The proposed image alignment system consists of two main components: the development of Fourier moment matching system and the implementation of the system in GPU. The Fourier moment matching is to efficiently find the location, orientation and size of the template from an input image. The GPU implementation speeds up the computation of the Fourier moment matching for the image alignment system to achieve real-time computation. |

| Wed, 24 Nov 2010 - wowowo | |
| Page Number Recognition for Reader Assistance System | |
| 曹瀠方, 葉家如, 謝涵宇, 江振國 | |
| In this project, the page number from one page of a book is identified. A webcam is attached on a table lamp. It captures the image of the current page when the reader is reading. To recognize the page number, the page area is first detected and the area of table or other irrelevant objects are removed. In the device setting, the camera doesn’t capture the image from a frontal view, a degree of 60 or 80 tilt is allowed. Thus, four corners of the book are detected to rectify the page shape. After the adjustment for lighting condition, point-set of “text” are extracted by edge detection. Lastly, a novel comparison based on distance measure for two point-sets is performed to identify the page number. |