- Multiple View Structure Reconstruction
- 3D Face Modeling
- Geometry Modeling and Processing
- 3D Stereo Vision
- Multiview People Localization and Tracking
- 3D Object Pose Estimation
- Lighting Estimation
Multiple View Structure Reconstruction
| Tue, 24 Jul 2018 - intern_james | |
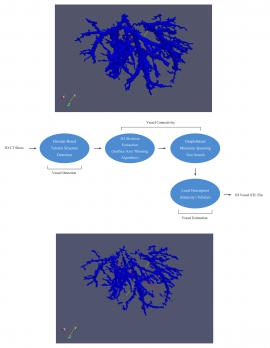
| 3D Liver Vessel Reconstruction from CT Images | |
| Xing-Chen Pan , Hong-Ren Su, Shang-Hong Lai, Kai-Che Liu , Hurng-Sheng Wu | |
| We propose a novel framework for reconstructing 3D liver vessel model from CT images. The proposed algorithm consists of vessel detection, vessel tree reconstruction and vessel radius estimation. First, we employ the tubular-filter based approach to detect vessel structure and construct the minimum spanning tree to bridge all the gaps between vessels. Then, we propose an approach to estimate the radius of the vessel at all vessel centerline voxels based on the local patch descriptors. Using the proposed 3D vessel reconstruction system can provide detailed 3D liver vessel model very efficiently. Our experimental results demonstrate the accuracy of the proposed system for 3D liver vessel reconstruction from 3D CT images. |
| Tue, 24 Jul 2018 - intern_james | |
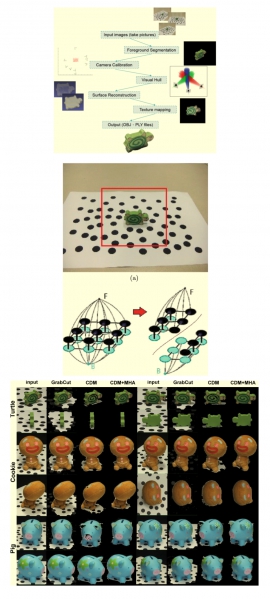
| 3D Reconstruction with Automatic Foreground Segmentation from Multi-View images Acquired from a Mobile Device | |
| Ping-Cheng Kuo, Chao-An Chen, Hsing-Chun Chang, Te-Feng Su, Shang-Hong Lai | |
| We propose a novel foreground object segmentation algorithm for a silhouette-based 3D reconstruction system. Our system requires several multi-view images as input to reconstruct a complete 3D model. The proposed foreground segmentation algorithm is based on graph-cut optimization with the energy function developed for planar background assumption. We parallelize parts of our program with GPU programming. The 3D reconstruction system consists of camera calibration, foreground segmentation, visual hull reconstruction, surface reconstruction, and texture mapping. The proposed 3D reconstruction process is accelerated with GPU implementation. In the experimental result, we demonstrate the improved accuracy by using the proposed segmentation method and show the reconstructed 3D models computed from several image sets. |
| Tue, 24 Jul 2018 - intern_james | |
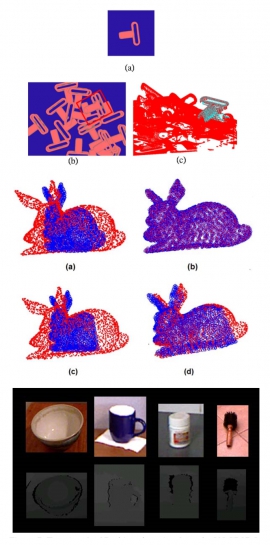
| Fast 3D Object Alignment from Depth Image with 3D Fourier Moment Matching on GPU | |
| Hong-Ren Su, Hao-Yuan Kuo, Shang-Hong Lai, Chin-Chia Wu | |
| In this paper, we develop a fast and accurate 3D object alignment system which can be applied to detect objects and estimate their 3D pose from a depth image containing cluttered background. The proposed 3D alignment system consists of two main algorithms: the first is the 3D detection algorithm todetect the top-levelobject from adepth map of the cluttered 3D objects, and the second is the 3D Fourierbased point-set alignment algorithm to estimate the 3D object pose from an input depth image. We also implement the proposed 3D alignment algorithm on a GPU computing platform to speed up the computation of the object detection and Fourier-based image alignment algorithms in order to align the 3D object in real time. |
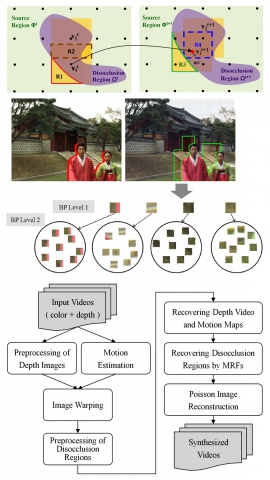
| Fri, 20 Jul 2018 - intern_james | |
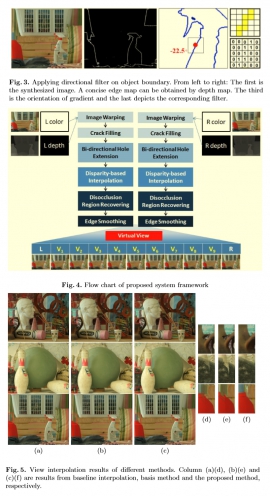
| Global optimization for spatio-temporally consistent view synthesis | |
| H.-A. Hsu, C.-K. Chiang and S.-H. Lai | |
| We propose a novel algorithm to generate a virtual-view video from a video-plus-depth sequence. The proposed method enforces the spatial and temporal consistency in the disocclusion regions by formulating the problem as an energy minimization problem in a Markov random field (MRF) framework. In the system level, we first recover the depth images and the motion vector maps after the image warping with the preprocessed depth map. Then we formulate the energy function for the MRF with additional shift variables for each node. To reduce the high computational complexity of applying BP to this problem, we present a multi-level BPs by using BP with smaller numbers of label candidates for each level. Finally, the Poisson image reconstruction is applied to improve the color consistency along the boundary of the disocclusion region in the synthesized image. Experimental results demonstrate the performance of the proposed method on several publicly available datasets. |
| Fri, 20 Jul 2018 - intern_james | |
| Novel Multi-view Synthesis from a Stereo Image Pair for 3D Display on Mobile Phone | |
| C. H. Wei, C. K. Chiang, Y. W. Sun, M. H. Lin, S. H. Lai | |
| In this paper we present a novel view synthesis method for mobile platform. A disparity-based view interpolation is proposed to synthesize the virtual view from a left and right image pair. This makes to full use of the available information of both images to give accurate interpolation results and greatly decreases the pixel number in the disoccusion region, thus reducing the errors introduced by the patch-based image inpainting. Two boundary refining schemes considering gradient and color coherence and applying directional filters on boundaries are proposed to improve the synthesized results. Experimental results show that the proposed method is effective and suitable for mobile environment. |

| Fri, 20 Jul 2018 - intern_james | |
| Accurate depth map estimation from video via MRF optimization | |
| S.-P. Tseng and S.-H. Lai | |
| In this paper, we propose a novel system to estimate depth maps of outdoor scenes from a video sequence. According to the characteristics of a video, our approach considers more information in the temporal domain than the traditional depth reconstruction methods. We perform Structure From Motion (SfM) on consecutive image frames from a video from SIFT feature point correspondences, which provides some camera information, including 3D translation and rotation, for all the images. Then, we compute the constrained optical flow between selected scenes so that we can solve an over-constrained linear system to estimate the depth map for all pixels at each frame. In addition, mean shift image segmentation is incorporated to aggregate the depth estimation. Thus, this initial depth map is used as the data term of our pixel-based and region-based Markov Random Field (MRF) formulation for depth map estimation. The proposed MRF depth estimation not only imposes adaptive smoothness constraints but also includes sky detection in the final depth map estimation. By minimizing the associated MRF energy function for each frame, we obtain refined depth maps that achieve detail-preserving and temporally consistent depth estimation results. |
| Fri, 20 Jul 2018 - intern_james | |
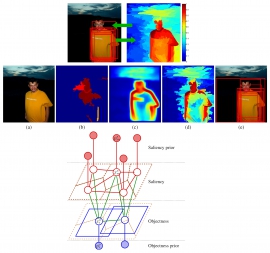
| Fusing generic objectness and visual saliency for salient object detection | |
| K.-Y. Chang, T.-L. Liu | |
| We present a novel computational model to explore the relatedness of objectness and saliency, each of which plays an important role in the study of visual attention. The proposed framework conceptually integrates these two concepts via constructing a graphical model to account for their relationships, and concurrently improves their estimation by iteratively optimizing a novel energy function realizing the model. Specifically, the energy function comprises the objectness, the saliency, and the interaction energy, respectively corresponding to explain their individual regularities and the mutual effects. Minimizing the energy by fixing one or the other would elegantly transform the model into solving the problem of objectness or saliency estimation, while the useful information from the other concept can be utilized through the interaction term. Experimental results on two benchmark datasets demonstrate that the proposed model can simultaneously yield a saliency map of better quality and a more meaningful objectness output for salient object detection. |

| Thu, 25 Nov 2010 - yilin | |
| Contour-Based Structure from Reflection | |
| Po-Hao Huang and Shang-Hong Lai | |
| In this paper, we propose a novel contour-based algorithm for 3D object reconstruction from a single uncalibrated image acquired under the setting of two plane mirrors. With the epipolar geometry recovered from the image and the properties of mirror reflection, metric reconstruction of an arbitrary rigid object is accomplished without knowing the camera parameters and the mirror poses. For this mirror setup, the epipoles can be estimated from the correspondences between the object and its reflection, which can be established automatically from the tangent lines of their contours. By using the property of mirror reflection as well as the relationship between the mirror plane normal with the epipole and camera intrinsic, we can estimate the camera intrinsic, plane normals and the orientation of virtual cameras. The positions of the virtual cameras are determined by minimizing the distance between the object contours and the projected visual cone for a reference view. After the camera parameters are determined, the 3D object model is constructed via the image-based visual hulls (IBVH) technique. The 3D model can be refined by integrating the multiple models reconstructed from different views. The main advantage of the proposed contour-based Structure from Reflection (SfR) algorithm is that it can achieve metric reconstruction from an uncalibrated image without feature point correspondences. Experimental results on synthetic and real images are presented to show its performance. | |
| IEEE Conf. on Computer Vision & Pattern Recognition (CVPR'06), New York, USA, Jun. 17-22, 2006. | (pdf) |
| Thu, 25 Nov 2010 - wei | |
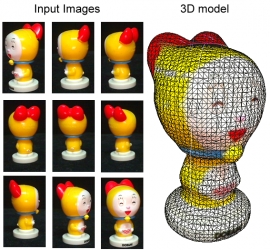
| Turntable 3D model reconstruction | |
| Po-Hao Huang, Chia-Ming Cheng, Hsiao-Wei Chen,Hao-Liang Yang, Li-Hsuan Chin and Shang-Hong Lai | |
| In this project, we developed a 3D model reconstruction system. Using a turntable, we can take photo of object easily in different pose. By using the camera calibration method which is proposed by Po-Hao Huang, we can get all points in 3D model, and we used visual hull reconstruct surface of the 3D model. In final step, we merge all images into a seamless texture map. |

| Thu, 25 Nov 2010 - yilin | |
| Silhouette-Based Camera Calibration from Sparse Views under Circular Motion | |
| Po-Hao Huang and Shang-Hong Lai | |
| In this paper, we propose a new approach to camera calibration from silhouettes under circular motion with minimal data. We exploit the mirror symmetry property and derive a common homography that relates silhouettes with epipoles under circular motion. With the epipoles determined, the homography can be computed from the frontier points induced by epipolar tangencies. On the other hand, given the homography, the epipoles can be located directly from the bi-tangent lines of silhouettes. With the homography recovered, the image invariants under circular motion and camera parameters can be determined. If the epipoles are not available, camera parameters can be determined by a low-dimensional search of the optimal homography in a bounded region. In the degenerate case, when the camera optical axes intersect at one point, we derive a closed-form solution for the focal length to solve the problem. By using the proposed algorithm, we can achieve camera calibration simply from silhouettes of three images captured under circular motion. Experimental results on synthetic and real images are presented to show its performance. |
3D Face Modeling
| Wed, 24 Nov 2010 - Savan | |
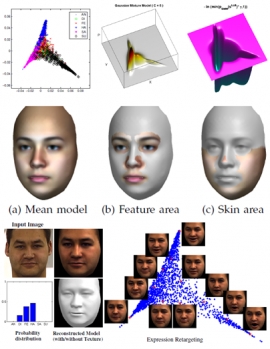
| The System for Reconstructing 3D Shape and Expression Deformation from a Single Face Image | |
| Shu-Fan Wang and Shang-Hong Lai | |
| Facial expression modeling is central to facial expression recognition and expression synthesis for facial animation. In this work, we propose a manifold-based 3D face reconstruction approach to estimating the 3D face model and the associated expression deformation from a single face image. In the training phase, we build a nonlinear 3D expression manifold from a large set of 3D facial expression models to represent the facial shape deformations due to facial expressions. Then a Gaussian mixture model in this manifold is learned to represent the distribution of expression deformation. By combining the merits of morphable neutral face model and the low-dimensional expression manifold, a novel algorithm is developed to reconstruct the 3D face geometry as well as the 3D shape deformation from a single face image with expression in an energy minimization framework. To construct the manifold for the facial expression deformations, we also propose a robust weighted feature map (RWF) based on the intrinsic geometry property of human faces for robust 3D non-rigid registration. Experimental results on CMU-PIE image database and FG-Net video database are shown to validate the effectiveness and accuracy of the proposed algorithm. | |
| sdsds | (sdsdsd) |

| Wed, 24 Nov 2010 - Savan | |
| Reconstructing 3D Shape, Albedo and Illumination from a Single Face Image | |
| Shu-Fan Wang and Shang-Hong Lai | |
| In this project, we propose a geometrically consistent algorithm to reconstruct the 3D face shape and the associated albedo from a single face image iteratively by combining the morphable model and the SH model. The reconstructed 3D face geometry can uniquely determine the SH bases, therefore the optimal 3D face model can be obtained by minimizing the error between the input face image and a linear combination of the associated SH bases. In this way, we are able to preserve the consistency between the 3D geometry and the SH model, thus refining the 3D shape reconstruction recursively. Furthermore, we present a novel approach to recover the illumination condition from the estimated weighting vector for the SH bases in a constrained optimization formulation independent of the 3D geometry. Experimental results show the effectiveness and accuracy of the proposed face reconstruction and illumination estimation algorithm under different face poses and multiple-light-source illumination conditions. |
Geometry Modeling and Processing
| Tue, 24 Jul 2018 - intern_james | |
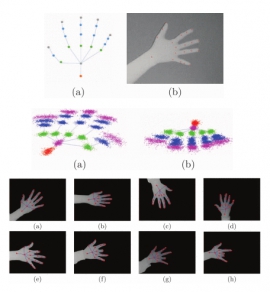
| 3D hand skeleton model estimation from a depth image | |
| Chin-Yun Fan, Meng-Hsuan Lin, Te-Feng Su, Shang-Hong Lai, Chih-Hsiang Yu | |
| In this paper, we present an algorithm for estimating 3D hand skeleton model from a single depth image based on the Active Shape Model framework. We first collect a large amount of training depth images, representing all articulated hand shape variations, and a set of hand joint points are labeled on these depth images. To accommodate the wide variations of hand articulations, we represent the hand skeleton model with multiple PCA models that are learned from the training data. In the search stage, we iteratively compute the translation and rotation from the hand depth information and fit the 3D hand skeleton model with the multiple PCA models. In addition, we modify the model fitting procedure to handle the partial occlusion problem when only some fingers are visible. In our experiments, we demonstrate the proposed algorithm on our hand depth image datasets to show the effectiveness and robustness of the proposed algorithm. |
| Tue, 24 Jul 2018 - intern_james | |
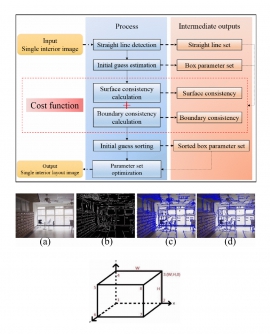
| Using Line Consistency to Estimate 3D Indoor Manhattan Scene Layout from a Single Image | |
| Hsing-Chun Chang, Szu-Hao Huang, and Shang-Hong Lai, | |
| In this paper, an optimization approach is proposed to estimate the 3D indoor Manhattan scene layout from a single input image. The proposed system models the interior space as a three-dimensional box which includes ceiling, floor, and walls. The regions corresponding to different surfaces can be calculated by projecting the 3D box onto the two-dimensional image with suitable camera and box parameters. This paper also utilizes the consistency of coplanar lines and the boundary edges between different surfaces to design a cost function. The rotation, translation, and box parameters of the interior layout can be estimated with an energy minimization process. In the experimental results, we apply the proposed algorithm to a number of real images of interior scenes to demonstrate the effectiveness of the proposed system. |
| Fri, 20 Jul 2018 - intern_james | |
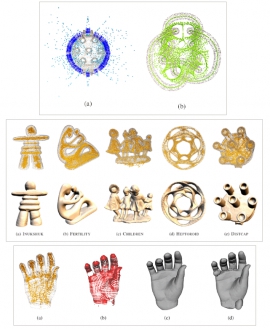
| Bipartite Polar Classification for Surface Reconstruction | |
| Y.-L. Chen, T.-Y. Lee, B.-Y. Chen, S.-H. Lai | |
| In this paper, we propose bipartite polar classification to augment an input unorganized point set ℘ with two disjoint groups of points distributed around the ambient space of ℘ to assist the task of surface reconstruction. The goal of bipartite polar classification is to obtain a space partitioning of ℘ by assigning pairs of Voronoi poles into two mutually invisible sets lying in the opposite sides of ℘ through direct point set visibility examination. Based on the observation that a pair of Voronoi poles are mutually invisible, spatial classification is accomplished by carving away visible exterior poles with their counterparts simultaneously determined as interior ones. By examining the conflicts of mutual invisibility, holes or boundaries can also be effectively detected, resulting in a hole‐aware space carving technique. With the classified poles, the task of surface reconstruction can be facilitated by more robust surface normal estimation with global consistent orientation and off‐surface point specification for variational implicit surface reconstruction. We demonstrate the ability of the bipartite polar classification to achieve robust and efficient space carving on unorganized point clouds with holes and complex topology and show its application to surface reconstruction. |

| Thu, 19 Jul 2018 - intern_james | |
| Recovering Depth Map from Video with Moving Objects | |
| H.-W. Chen and S.-H. Lai | |
| In this paper, we propose a novel approach to reconstructing depth map from a video sequence, which not only considers geometry coherence but also temporal coherence. Most of the previous methods of reconstructing depth map from video are based on the assumption of rigid motion, thus they cannot provide satisfactory depth estimation for regions with moving objects. In this work, we develop a depth estimation algorithm that detects regions of moving objects and recover the depth map in a Markov Random Field framework. We first apply SIFT matching across frames in the video sequence and compute the camera parameters for all frames and the 3D positions of the SIFT feature points via structure from motion. Then, the 3D depths at these SIFT points are propagated to the whole image based on image over-segmentation to construct an initial depth map. Then the depth values for the segments with large reprojection errors are refined by minimizing the corresponding re-projection errors. In addition, we detect the area of moving objects from the remaining pixels with large re-projection errors. In the final step, we optimize the depth map estimation in a Markov random filed framework. Some experimental results are shown to demonstrate improved depth estimation results of the proposed algorithm. |

| Sun, 19 Dec 2010 - yilin | |
| Binary Orientation Trees for Volume and Surface Reconstruction from Unoriented Point Clouds | |
| Yi-Ling Chen, Bing-Yu Chen, Shang-Hong Lai and Tomoyuki Nishita | |
| Given a complete unoriented point set, we propose to build a binary orientation tree (BOT) for volume and surface representation, which roughly splits the space into the interior and exterior regions with respect to the input point set. The BOTs are constructed by performing a traditional octree subdivision technique while the corners of each cell are associated with a tag indicating the in/out relationship with respect to the input point set. Starting from the root cell, a growing stage is performed to efficiently assign tags to the connected empty sub-cells. The unresolved tags of the remaining cell corners are determined by examining their visibility via the hidden point removal operator. We show that the outliers accompanying the input point set can be effectively detected during the construction of the BOTs. After removing the outliers and resolving the in/out tags, the BOTs are ready to support any volume or surface representation techniques. To represent the surfaces, we also present a modified MPU implicits algorithm enabled to reconstruct surfaces from the input unoriented point clouds by taking advantage of the BOTs. | |
| Computer Graphics Forum (Proceedings of Pacific Graphics 2010), vol.29, no. 7, pp2011-2019, Sep. 2010. | (slides) |
| Thu, 25 Nov 2010 - rily | |
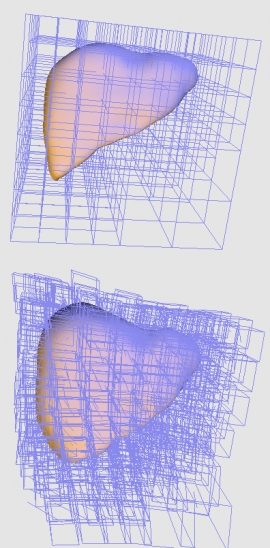
| 3D Non-rigid Registration for MPU Implicit Surfaces | |
| Tung-Ying Lee and Shang-Hong Lai | |
| Implicit surface representation is well suited for surface reconstruction from a large amount of 3D noisy data points with non-uniform sampling density. Previous 3D non-rigid model registration methods can only be applied to the mesh or volume representations, but not directly to implicit surfaces. To our best knowledge, the previous 3D registration methods for implicit surfaces can only handle rigid transformation and they must keep the data points on the surface. In this paper, we propose a new 3D non-rigid registration algorithm to register two multi-level partition of unity (MPU) implicit surfaces with a variational formulation. The 3D non-rigid transformation between two implicit surfaces is a continuous deformation function, which is determined via an energy minimization procedure. Under the octree structure in the MPU surface, each leaf cell is transformed by an individual affine transformation associated with an energy that is related to the distance between two general quadrics. The proposed algorithm can directly register between two 3D implicit surfaces without sampling on the two signed distance functions or polygonalizing implicit surfaces, which makes our algorithm efficient in both computation and memory requirement. Experimental results on 3D human organ and sculpture models demonstrate the effectiveness of the proposed algorithm. | |
| CVPR'08 Workshop on Non-Rigid Shape Analysis and Deformable Image Alignment (NORDIA), 2008 | (slides) |
| Wed, 24 Nov 2010 - Savan | |
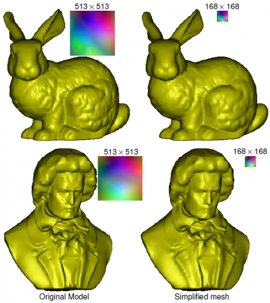
| Geometry Image Resizing and Mesh Simplification | |
| Shu-Fan Wang, Yi-Ling Chen, Chen-Kuo Chiang and Shang-Hong Lai | |
| Polygonal meshes are widely used to represent the shape of 3D objects and the generation of multi-resolution models has been a significant research topic in computer graphics. In this project, we demonstrate how to generate multi-resolution models through 2D image processing techniques. The goal of generating multi-resolution models is accomplished by resizing the corresponding geometry images of 3D models. By defining appropriate energy on 2D images reflecting the importance of 3D vertices, we propose a modified content-aware image resizing algorithm suitable for geometry images, which achieves the preservation of salient structures and features in 3D models as well. We evaluate various image resizing techniques and show experimental results to validate the effectiveness of the proposed algorithm. |
3D Stereo Vision
| Fri, 10 Aug 2018 - intern_james | |
| Geodesic tree-based dynamic programming for fast stereo reconstruction | |
| C.-H. Sin, C.-M. Cheng, S.-H. Lai, S.-Y. Yang | |
| In this paper, we present a novel tree-based dynamic programming (TDP) algorithm for efficient stereo reconstruction. We employ the geodesic distance transformation for tree construction, which results in sound image over-segmentation and can be easily parallelized on graphic processing unit (GPU). Instead of building a single tree to convey message in dynamic programming (DP), we construct multiple trees according to the image geodesic distance to allow for parallel message passing in DP. In addition to efficiency improvement, the proposed algorithm provides visually sound stereo reconstruction results. Compared with previous related approaches, our experimental results demonstrate superior performance of the proposed algorithm in terms of efficiency and accuracy. | |
| Hh | (Bhh) |
| Hh | (Bhh) |
| V | (G) |
{kind=link}
| Mon, 23 Jul 2018 - intern_james | |
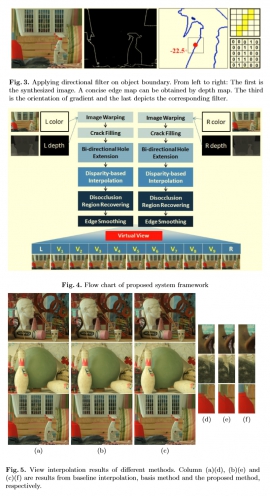
| Novel 3D video conversion from down-sampled stereo video | |
| W.-T. Lin and S.-H. Lai | |
| Stereo video has become the main-stream 3D video format in recent years due to its simplicity in data representation and acquisition. Under stereo settings, the twin problems of video super-resolution and high-resolution disparity estimation are intertwined. In this paper, we present a novel 3D video conversion system that converts down-sampled stereo video to high-resolution stereo sequences with a Bayesian framework. In addition, we estimate the finer-resolution disparity maps with a two-step CRF model. Our super-resolution system can also be incorporated into the video coding process, which can significantly lower the data amount as well as preserving high-quality details. Experimental results demonstrate that our system can enhance image resolution in both stereo video and disparity map. Objective evaluation of the proposed video coding scheme combined with super-resolution at different compression ratios also shows competitive performance of proposed system for video compression. |
| Thu, 19 Jul 2018 - intern_james | |
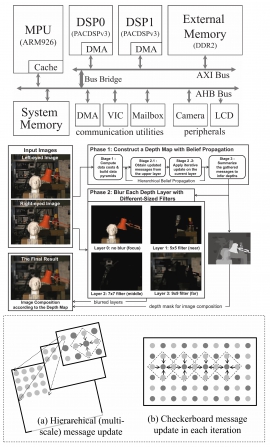
| Parallelization of a Bokeh application on embedded multicore DSP systems | |
| C.-B. Kuan, S.-C. Wang, W.-L. Shih, K.-H. Tsai | |
| Bokeh application presents the blur or the aesthetic quality of blurring in out-of-focus areas of an image. The out-of-focus effect of Bokeh results depends on accuracy of depth information and blurring effects produced by image postprocessing. To obtain accurate depth information, current stereo vision techniques however consume a huge amount of processing time. In this paper, we present a case study on parallelizing a Bokeh application on an embedded multicore platform, which features one MPU and one DSP sub-system consisting of two VLIW DSP processors. The Bokeh application employs a Belief Propagation method to obtain depth information of input images and uses the information to generate output images with out-of-focus effect. This study also illustrates how to deliver performance for applications on embedded multicore systems. To sustain heavy computation requirement of the stereo vision techniques, DSPs with their SIMD instructions are leveraged to exploit data parallelism in critical kernels. In addition, DMAs on the multicore system are also incorporated to facilitate data transmission between processors. The access to SIMD and DMAs is provided by two essential programming models we developed for embedded multicore systems. Our work also gives the firsthand experiences of how C++ classes and abstractions can be used to help parallelization of applications on embedded multicore DSP systems. Finally, in our experiments, we utilize DSPs, SIMD and DMAs to obtain performance for two key components of the Bokeh application with their speedups of 1.67 and 2.75, respectively. |
| Sun, 19 Dec 2010 - yilin | |
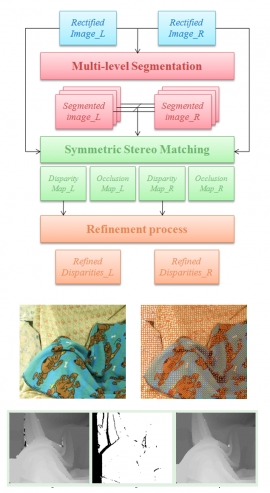
| Stereo Matching Algorithm Using Hierarchical Over-segmentation and Belief Propagation | |
| Li-Hsuan Chin | |
| In this work, we present a novel algorithm to infer disparity map from given a pair of rectified images. We first employ image over-segmentation to construct a Content-based Hierarchical Markov Random Field (CHMRF). This image representation contains two advantages for vision applications. One is the hierarchical MRF construction, and the other is the regular graph structure. The former has been widely applied to computer vision problems to improve the efficiency in MRF optimization. The latter can simplify the message passing and hardware implementation of MRF optimization techniques. After the construction of CHMRF, we perform symmetric stereo matching and occlusion handing using Hierarchical Belief Propagation (HBP) based on the proposed graphical model. Finally, a refinement process for the disparity map is introduced (e.g. plane fitting or bilateral filtering) to reduce the disparity errors caused by occlusion, textureless region or image noise, etc. Our experimental results show that we can efficiently obtain disparity maps of comparable accuracy when compared to most global stereo algorithms. For real stereo video sequences, we are able to accurately estimate the depth information for each frame with the pre-processing of robust self image rectification. | |
| Master Thesis, Department of Computer Science, National Tsing Hua University, Hsinchu, Taiwan. | (pdf) |

| Thu, 25 Nov 2010 - yilin | |
| Improved Novel View Synthesis from Depth Image with Large Baseline | |
| Chia-Ming Cheng, Shu-Jyuan Lin, Shang-Hong Lai, Jinn-Cherng Yang | |
| In this paper, a new algorithm is developed for recovering the large disocclusion regions in depth image based rendering (DIBR) systems on 3DTV. For the DIBR systems, undesirable artifacts occur in the disocclusion regions by using the conventional view synthesis techniques especially with large baseline.Three techniques are proposed to improve the view synthesis results. The first is the preprocessing of the depth image by using the bilateral filter, which helps to sharpen the discontinuous depth changes as well as to smooth the neighboring depth of similar color, thus restraining noises from appearing on the warped images. Secondly, on the warped image of a new viewpoint, we fill the disocclusion regions on the depth image with the background depth levels to preserve the depth structure. For the color image, we propose the depth-guided exemplar-based image inpainting that combines the structural strengths of the color gradient to preserve the image structure in the restored regions. Finally, a trilateral filter, which simultaneous combines the spatial location, the color intensity, and the depth information to determine the weighting, view synthesis algorithm compared to the traditional methods. | |
| In Proc. of International Conference on Pattern Recognition (ICPR), Tampa, Florida, U.S.A., Dec. 2008. | (pdf) |

| Thu, 25 Nov 2010 - yilin | |
| Geodesic Tree-Based Dynamic Programming for Fast Stereo Reconstruction | |
| Chin-Hong Sin, Chia-Ming Cheng, Shang-Hong Lai and Shan-Yung Yang | |
| In this paper, we present a novel tree-based dynamic programming (TDP) algorithm for efficient stereo reconstruction. We employ the geodesic distance transformation for tree construction, which results in sound image over-segmentation and can be easily parallelized on graphic processing unit (GPU). Instead of building a single tree to convey message in dynamic programming (DP), we construct multiple trees according to the image geodesic distance to allow for parallel message passing in DP. In addition to efficiency improvement, the proposed algorithm provides visually sound stereo reconstruction results. Compared with previous related approaches, our experimental results demonstrate superior performance of the proposed algorithm in terms of efficiency and accuracy. | |
| IEEE Embedded Computer Vision Workshop (ICCV Workshops), Kyoto, Japan, Oct. 2009. | (pdf) |
Multiview People Localization and Tracking
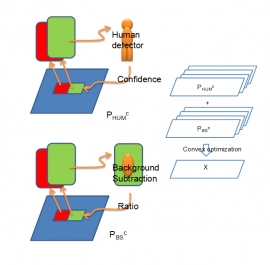
| Thu, 25 Nov 2010 - rily | |
| People Localization in a Camera Network Combining Background Subtraction and Scene-Aware Human Detection | |
| Tung-Ying Lee, Tsung-Yu Lin, Szu-Hao Huang, Shang-Hong Lai, and Shang-Chih Hung | |
| In a network of cameras, people localization is an important issue. Traditional methods utilize camera calibration and combine results of background subtraction in different views to locate people in the three dimensional space. Previous methods usually solve the localization problem iteratively based on background subtraction results, and high-level image information is neglected. In order to fully exploit the image information, we suggest incorporating human detection into multi-camera video surveillance. We develop a novel method combining human detection and background subtraction for multi-camera human localization by using convex optimization. This convex optimization problem is independent of the image size. In fact, the problem size only depends on the number of interested locations in ground plane. Experimental results show this combination performs better than background subtraction-based methods and demonstrate the advantage of combining these two types of complementary information. |
3D Object Pose Estimation
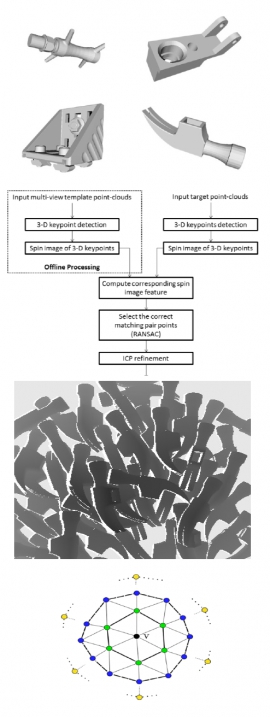
| Tue, 24 Jul 2018 - intern_james | |
| 3D object detection and pose estimation from depth image for robotic bin picking | |
| Hao-Yuan Kuo, Hong-Ren Su, Shang-Hong Lai, Chin-Chia Wu | |
| In this paper, we present a system for automatic object detection and pose estimation from a single depth map containing multiple objects for bin-picking applications. The proposed object detection algorithm is based on matching the keypoints extracted from the depth image by using the RANSAC algorithm with the spin image descriptor. In the proposed system, we combine the keypoint detection and the RANSAC algorithm to detect the objects, followed by the ICP algorithm to refine the 3D pose estimation. In addition, we implement the proposed algorithm on the GPGPU platform to speed-up the computation. Experimental results on simulated depth data are shown to demonstrate the proposed system. |
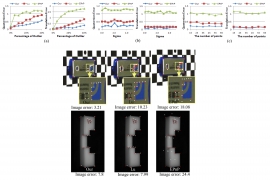
| Thu, 19 Jul 2018 - intern_james | |
| Robust 3D object pose estimation from a single 2D image | |
| C.-M. Cheng, H.-W. Chen, S.-H. Lai, and Y.-H. Tsai | |
| In this paper, we propose a robust algorithm for 3D object pose estimation from a single 2D image. The proposed pose estimation algorithm is based on modifying the traditional image projection error function to a sum of squared image projection errors weighted by their associated distances. By using an Euler angle representation, we formulate the energy minimization for the pose estimation problem as searching a global minimum solution. Based on this framework, the proposed algorithm employs robust techniques to detect outliers in a coarse-to-fine fashion, thus providing very robust pose estimation. Our experiments show that the algorithm outperforms previous methods under noisy conditions. |
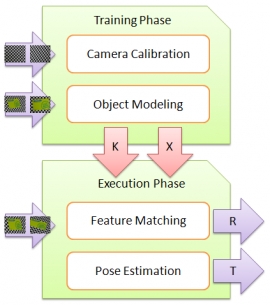
| Thu, 25 Nov 2010 - wei | |
| 3D Object Pose Estimation | |
| Tung-Ying Lee, Hsiao-Wei Chen, Hong-Ren Su and Shang-Hong Lai | |
| The goal of this project is to develop a novel 3D object alignment technique for industrial robot 3D object localization. The alignment system will consist of two main components: 2D local pattern alignment and 2D-3D pose estimation. The 2D local pattern alignment component is to quickly find 2D affine alignments of some selected local patches based on the Fourier-based image matching technique. The affine alignment results are then sent to the second stage, which is to solve the 2D-3D pose estimation problem in computer vision. In this stage, an optimization-based pose estimation procedure is applied to estimate the 3D pose of the object from the 2D correspondences of some local patches. The proposed alignment technique is based on the matching of the geometric information so that the alignment system is robust against lighting changes. |
Lighting Estimation
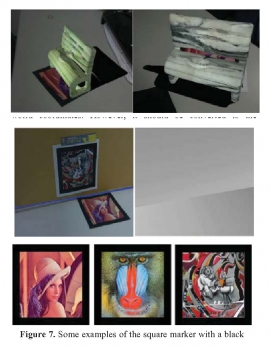
| Tue, 24 Jul 2018 - intern_james | |
| Lighting estimation from a single image containing multiple planes | |
| P.-C. Kuo and S.-H. Lai | |
| In this paper, we present a novel lighting estimation algorithm for the scene containing two or more planes. This paper focuses on near point light source estimation. We first detect planar markers to estimate the poses of the 3D planes in the scene. Then we estimate the shading image from the captured image. A near point light source lighting model is used to define an objective function for light source estimation in this paper. The output of the proposed method is the lighting parameters estimated from minimizing the objective function. In the experiments, we test the proposed algorithm on synthetic data and real dataset. Our experimental results show the proposed algorithm outperforms the state-of-the-art lighting estimation method. Moreover, we develop an augmented reality system that includes lighting estimation by using the proposed algorithm. |